1 Some Random Notes On Bigdata¶
1.1 References¶
1.1.1 Apache Sparc¶
- Sparc white paper: http://www-bcf.usc.edu/~minlanyu/teach/csci599-fall12/papers/nsdi_spark.pdf
- Sparc Streaming white paper: https://www2.eecs.berkeley.edu/Pubs/TechRpts/2012/EECS-2012-259.pdf
- Databricks free MOOC course: https://www.edx.org/course/big-data-analysis-apache-spark-uc-berkeleyx-cs110x
- Databricks community edition: https://databricks.com/blog/2016/02/17/introducing-databricks-community-edition-apache-spark-for-all.html
1.1.2 Hadoop¶
- Google Paper 2004 http://research.google.com/archive/mapreduce.html
- Hadoop Design Patterns O’Reily Book
- Hortonworks Data Platform: Learning Ropes: http://hortonworks.com/hadoop-tutorial/learning-the-ropes-of-the-hortonworks-sandbox/
- Hadoop Architecture Book: - http://slideshare.com/hadooparchbook - http://github.com/hadoparchitecturebook
- Good presentation with reference architecture: http://www.slideshare.net/PhilippeJulio/hadoop-architecture
- Good Highlevel Pseudo code http://www.slideshare.net/emcacademics/milind-hadoop-trainingbrazil
- Good Hadoop Internals Architecture: http://www.slideshare.net/EmilioCoppa/hadoop-internals
1.1.4 Tools¶
- Terraform - Heterogenous cloud resources management tool: https://www.terraform.io/downloads.html
1.2 Hadoop¶
1.2.1 Architecture¶
Apache Hadoop is a software solution for distributed computing of large datasets. Hadoop provides a distributed filesystem (HDFS) and a MapReduce implementation.
Hadoop project organized in 4 projects:
- Common (145 config parameters)
- HDFS (173 config parameters)
- YARN (115 config parameters)
- MapReduce (195 config parameters)
2.5 million lines of code – i.e. 2,500,000 lines. 81 contributors. Roughly, 60% Hortonworks, 30% Cloudera and 10% Yahoo contribution. Original author Doug Cutting currently works at Cloudera.
Designed for scalability and fault tolerance. For 1000 nodes cluster, MTTF is < 1 day. 1000 nodes cluster with each machine 16GB RAM, 1TB disk has total 16TB memory and 1 Petabyte disk. Hadoop designed to process Petabytes of data.
HDFS exposes block placement so that computation can be moved to data.
- You can filter and aggregate data.
- Map Reduce functions written in Java. Also possible: C++, Python, Per, etc.
- In std config HDFS saves all files 3 times on different nodes. The “name node” has info where the files are stored.
- Follows MapRecuce principle (published by Google)
See http://ercoppa.github.io/HadoopInternals/
---------------------------------------------------------------------
Map Reduce Framework
---------------------------------------------------------------------
YARN HDFS Storage
Infra Manager Federation (S3, Disk, etc)
---------------------------------------------------------------------
Cluster
---------------------------------------------------------------------
The YARN Infrastructure (Yet Another Resource Negotiator) is the framework responsible for providing the computational resources (e.g., CPUs, memory, etc.) needed for application executions. YARN is independent of HDFS – it does not manage storage and is not required by HDFS.
YARN uses the Resource Manager (one per cluster) which is the master and node managers (one per node).
The job is submitted to YARN resource manager (which is single point of failure) which schedules the job using node managers.
The Application Master is responsible for the execution of a single application. It asks for containers to the Resource Scheduler (Resource Manager) and executes specific programs (e.g., the main of a Java class) on the obtained containers.
The Application Master knows the application logic and thus it is framework-specific.
The MapReduce framework provides its own implementation of an Application Master.
--------------------------------------------------------------------------
Job Submitter
--------------------------------------------------------------------------
YARN Resource Manager (uses Resource Scheduler)
--------------------------------------------------------------------------
Node Manager (One per slave)
--------------------------------------------------------------------------
Container (Many per node. Each container represents vcores, memory)
--------------------------------------------------------------------------
Application Master runs on a container to execute part of the Job.
--------------------------------------------------------------------------
HDFS used for input/output but not for intermediate storage by MapReduce.
Map is inherently parallel. Reduce is inherently sequential (with scope for parallelism in some cases).
1.2.2 MR Job Contents¶
When a client submits an application, several kinds of information are provided to the YARN infrastucture. In particular:
a configuration: this may be partial (use default values when absent) Notice that these default values may be the ones chosen by a Hadoop provider like Amazon.
A JAR containing:
- a map() implementation
- a combiner implementation
- a reduce() implementation
- Input and output information: input directory: is the input directory on HDFS? On S3? How many files?
- output directory: where will we store the output? On HDFS? On S3?
1.2.3 How many Map Tasks?¶
The number of files inside the input directory is a factor for deciding the number of Map Tasks of a job.
The Application Master will launch one MapTask for each map split. Typically, there is a map split for each input file. If the input file is too big (bigger than the HDFS block size) then we have two or more map splits associated to the same input file.
1.2.4 MapTask Launch¶
The MapReduce Application Master asks to the Resource Manager for Containers needed by the Job: one MapTask container request for each MapTask (map split).
A container request for a MapTask tries to exploit data locality of the map split.
The Application Master asks for:
- a container located on the same Node Manager where the map split is stored
- otherwise, a container located on a Node Manager in the same rack where the the map split is stored;
- otherwise, a container on any other Node Manager of the cluster
Map output is stored in-memory and may spill over to local disk when there is buffer overflow. If there is a spill, it is done using multiple files one per partition i.e. reducer. The combiner function is run as local reducer. Finally the output file partitions are made available to reducer over HTTP.
Note: There is file system overhead as part of communication from Map task to Reduce task if the output file size is more than 25% NodeManager memory. Otherwise in-memory output is created.
You can configure UBER mode which is MapReduce job for small dataset. An Uber task means that the ApplicationMaster uses its own JVM to run Map and Reduce tasks, so the tasks are executed sequentially on one node. In this case YARN has to allocate a container for ApplicationMaster only.
You can set mapreduce.job.ubertask.enable=true; to enable uberization for small jobs. An example Hive session to run uberized task which has no reducer job at all
set mapreduce.job.ubertask.enable=true;
set mapreduce.map.memory.mb=1000; # Anything which requires less than 1GB can be uberized.
set mapreduce.reduce.memory.mb=1000;
SELECT 'A' FROM dual WHERE 1=1;
1.2.5 How many Reduce Jobs ?¶
Depending on application you may want to have N reducers since you have N computing resources or you may require single reducer if the application is sort of global sort of all output. Anyway there is some default behaviour and you can customize this in application.
The number of ReduceTasks for the job is decided by the configuration parameter mapreduce.job.reduces.
What is the partitionIdx associated to an output tuple?
The paritionIdx of an output tuple is the index of a partition. It is decided inside the Mapper.Context.write():
partitionIdx = (key.hashCode() & Integer.MAX_VALUE) % numReducers
It is stored as metadata in the circular buffer alongside the output tuple. The user can customize the partitioner by setting the configuration parameter mapreduce.job.partitioner.class.
1.2.6 HDFS¶
There is single “name node” (single point of failure) and many datanodes.
1.2.7 Case Study¶
For search assist, we need auto completion.
Insight: Related concepts appear close together in text corpus
* Input: Web pages
* 1 Billion Pages, 10K bytes each
* 10 TB of input data
* Output: List(word, List(related words))
Think MapReduce:
* Record = (Key, Value)
* Key : Comparable, Serializable * Value: Serializable
* Input, Map, Shuffle, Reduce, Output
Pseudo Code:
# Search Assist // Input: List(URL, Text)
foreach URL in Input :
Words = Tokenize(Text(URL));
foreach word in Tokens :
Insert (word, Next(word, Tokens)) in Pairs;
Insert (word, Previous(word, Tokens)) in Pairs;
// Result: Pairs = List (word, RelatedWord)
Group Pairs by word;
// Result: List (word, List(RelatedWords)
foreach word in Pairs :
Count RelatedWords in GroupedPairs;
// Result: List (word, List(RelatedWords, count))
foreach word in CountedPairs : Sort Pairs(word, *) descending by count;
choose Top 5 Pairs; // Result: List (word, Top5(RelatedWords))
1.2.8 Hadoop Installation¶
- Install hadoop common using document:
- http://hadoop.apache.org/common/docs/r0.17.1/quickstart.html
1.2.9 Hadoop Standalone Operation¶
By default, Hadoop is configured to run things in a non-distributed mode, as a single Java process. This is useful for debugging.
The following example copies the unpacked conf directory to use as input and then finds and displays every match of the given regular expression. Output is written to the given output directory
$ mkdir input
$ cp conf/*.xml input
$ bin/hadoop jar hadoop-*examples.jar grep input output 'dfs[a-z.]+'
$ cat output/*
1 dfsadmin
Note: It searched all files in input directory and displayed the grep output
1.2.10 Pseudo-Distributed Operation¶
Hadoop can also be run on a single-node in a pseudo-distributed mode where each Hadoop daemon runs in a separate Java process.
1.2.11 Configuration¶
Hadoop’s Java configuration is driven by two types of important configuration files:
- Read-only default configuration - core-default.xml, hdfs-default.xml, yarn-default.xml and mapred-default.xml.
- Site-specific configuration - etc/hadoop/core-site.xml, etc/hadoop/hdfs-site.xml, etc/hadoop/yarn-site.xml and etc/hadoop/mapred-site.xml.
- Additionally, you can control the Hadoop scripts found in the bin/ directory of the distribution, by setting site-specific values via the etc/hadoop/hadoop-env.sh and etc/hadoop/yarn-env.sh. This defines optional parameters for the hadoop daemons.
- To configure the Hadoop cluster you need to configure env.sh files and xml files.
- HDFS daemons are NameNode, SecondaryNameNode, and DataNode.
- YARN damones are ResourceManager, NodeManager, and WebAppProxy.
- If MapReduce is to be used, then the MapReduce Job History Server will also be running.
- For large installations, these are generally running on separate hosts.
The configuration files (in 2.7.* releases) are:
/opt/hadoop/hadoop/etc $find . -name '*xml*'
./hadoop/capacity-scheduler.xml
./hadoop/kms-acls.xml
./hadoop/yarn-site.xml
./hadoop/hadoop-policy.xml
./hadoop/kms-site.xml
./hadoop/httpfs-site.xml
./hadoop/hdfs-site.xml
./hadoop/core-site.xml
etc/hadoop/slaves file lists all slave hostnames. By default it contains just 'localhost'.
1.2.12 Initial Setup¶
Now check that you can ssh to the localhost without a passphrase:
$ ssh localhost
If you cannot ssh to localhost without a passphrase, execute the following commands:
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
Execution
Format a new distributed-filesystem:
$ bin/hadoop namenode -format
Start The hadoop daemons:
$ bin/start-all.sh
The hadoop daemon log output is written to the ${HADOOP_LOG_DIR} directory
(defaults to ${HADOOP_HOME}/logs).
Browse the web-interface for the NameNode and the JobTracker, by default they
are available at:
NameNode - http://localhost:50070/
JobTracker - http://localhost:50030/
Copy the input files into the distributed filesystem:
$ bin/hadoop dfs -put conf input
Run some of the examples provided:
$ bin/hadoop jar hadoop-*-examples.jar grep input output 'dfs[a-z.]+'
Examine the output files:
Copy the output files from the distributed filesystem to the local filesytem
and examine them:
$ bin/hadoop dfs -get output output
$ cat output/*
or
View the output files on the distributed filesystem:
$ bin/hadoop dfs -cat output/*
When you're done, stop the daemons with:
$ bin/stop-all.sh
1.2.13 Hadoop Essential Components¶
Namenode - A daemon which provides info for available nodes and file replica location information. Single point of failure.
- Jobtracker and Tasktracker - What is jobtracker in 1.0 is replaced by 3 services in version 2.0:
- Resource manager service. Persistent. Like Jobtracker in 1.0. Accepts and runs client jobs. Daemon in Master node. This is single point of failure.
- Node Manager Service. Like Tasktracker in 1.0. A daemon running on slave. It manages set of task slots aka containers for that node. Each container represents (#cores, memory_slice). In future disk resources may be managed as container. Task slot may be assigned for either Map task or Reduce Task or Application Master.
- Job History Server provides information about status of job. One per job, terminated when job completes.
Datanode - One or mode nodes where HDFS data resides.
Zoo keeper - For HBase HMaster HA and HDFS 2.0 Resource Manager HA
Application master - Runs on any slave node as Job driver - one per job - MapReduce framework provides an implementation of application master.
1.2.14 Standard Hadoop Scripts¶
Script Name Functionality
bin/hadoop hadoop fs invokes hdfs client (dump or put files). hadoop jar invokes MapReduce job.
For yarn application, use yarn jar instead of hadoop jar. Config files in ../etc dir.
hadoop fs can mix files from hdfs, s3, local, etc file systems where as hdfs dfs is for hdfs only.
See Also:
http://stackoverflow.com/questions/18142960/whats-the-difference-between-hadoop-fs-shell-commands-and-hdfs-dfs-shell-co
bin/hdfs hdfs management script. Supported commands include:
dfs run a filesystem command on the file systems supported in Hadoop.
namenode -format format the DFS filesystem and/or invoke namenode daemon
datanode run a DFS datanode
dfsadmin E.g. hdfs dfsadmin -report ; lists all running name and data nodes.
nfs3 run an NFS version 3 gateway
getconf -namenodes Get list of namenodes in cluster.
etc.
sbin/start-dfs.sh Start namenode daemon and datanode daemon.
sbin/hadoop-daemon.sh Highlevel script to start any daemon like namenode/datanode/etc.
Invokes lower level script like hdfs after initializing proper env variables, etc.
sbin/hadoop-daemons.sh Highlevel script to start any daemon on all slaves as specified in etc/hadoop/slaves file.
bin/yarn Invokes yarn resource manager (master one per cluster) or node manager (one per slave).
sbin/start-yarn.sh Run this on master node to start both resource manager and node manager.
sbin/yarn-daemon.sh Highlevel script to invoke bin/yarn after setting up proper env variables.
sbin/yarn-daemons.sh Highlevel script to invoke bin/yarn on all nodes as configured in etc/hadoop/slaves file.
1.2.15 Standard Hadoop Processes¶
hadoop@hadoopnode1:~/hadoop-0.20.2/conf$ jps
9923 Jps
7555 NameNode
8133 TaskTracker
7897 SecondaryNameNode
7728 DataNode
7971 JobTracker
1.2.16 Hadoop Default ports¶
See ‘default.xml‘ files in hadoop/ install dir.
NameNode - http://localhost:50070/; For https 50470
DataNode - http://localhost:50075/; For https 50475; For data transfer port 50010
JobTracker - http://localhost:50030/
1.2.17 Running example programs¶
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
$ cat output/*
1.2.18 Map Reduce Configuration¶
mapreduce.framework.name can be one of local, classic or yarn.
1.3 Bigdata Technologies¶
1.3.1 HBase¶
An open source, non-relational, NoSQL, column oriented, distributed database modeled after Google’s BigTable and is written in Java Part of Hadoop core. NoSQL. Java. Mutable data on top of immutable HDFS. Phoenix gives SQL JDBC interface to HBASE.
HBASE components:
- Region Servers - Hosts the tables - Co-located along with HDFS datanodes.
- Hbase Master - Coordinating region servers - Co-located along with HDFS Namenode.
- ZooKeeper - HA config. Used to elect Hbase Master (and Namenode master). Monitors heartbeats from both HMaster and Region Servers. Each Region Server creates an ephemeral node (i.e. Node removed when server dies). The HMaster monitors these nodes to discover available region servers.
- HDFS - Used to store files/data in /apps/hbase/data directory.
- API - Java client API to HBASE.
- HBase Meta Table. This keeps a list of all regions in the system. This is like a b tree which contains region location for the key range.
- WAL - Write Ahead Logs - Each put request triggers writing into WAL first.
Can scale to millions of columns. Versioned data by time. Each entry is: ( Table, Row_key, Family, Column, Timestamp) = Cell-Value
A key-range is called a region.
Example
( 'key1', 'Animal-Family', 'Size', 1:00PM ) = 'Small'
( 'key1', 'Animal-Family', 'Size', 2:00PM ) = 'Big'
Example Table Creation
hbase> create 't1', 'f1', 'f2' # Creates table t1 with f1 and f2 as family-name fields.
hbase> create 't1', 'f1', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'} # supply some configs.
hbase> put 't1', 'id1', 'f1:city', 'Boston' # Insert column 'f1:city' with ID as 'id1' with value 'Boston'
hbase> list # List tables
hbase> scan 't1' # Dump all
HBase Tables are divided horizontally by row key range into ‘Regions.’ A region contains all rows in the table between the region’s start key and end key. Regions are assigned to the nodes in the cluster, called ‘Region Servers’, and these serve data for reads and writes. A region server can serve about 1,000 regions.
Problems with HBASE: Business continuity reliability:
- WAL replay slow - Slow complex crash recovery - Major Compaction I/O storms
- MapR Hbase provides faster recovery using micro WAL
1.3.2 Hive¶
Hive is just a tool which provides SQL interface to user to manipulate hadoop data in HDFS. It generates MAP/Reduce code from given SQL. It is not a database itself. Part of Hadoop Core. Written in Java. HQL.
Unlike Hive, HBase operations run in real-time on its database rather than MapReduce jobs. So Hive with HBASE is not apple to apple comparison. You can compare Hive with PIG script which also generates MAP/Reduce jobs for Hadoop data.
Hive enables developers not familiar with MapReduce to write data queries that are translated into MapReduce jobs in Hadoop.
Despite providing SQL functionality, Hive does not provide interactive querying yet - it only runs batch processes on Hadoop.
SQL queries are submitted to Hive and they are executed as follows:
- Hive compiles the query.
- An execution engine, such as Tez or MapReduce, executes the compiled query.
- The resource manager, YARN, allocates resources for applications across the cluster.
- The data files resides in HDFS (Hadoop Distributed File System).
- Hive also supports ‘external table’ where the existing [hdfs or local] data file may be used. Dropping of external table only drops meta-data, not the original file.
- Supported data formats are ORC, AVRO, Parquet, and text.
- Query results are then returned over a JDBC/ODBC connection.
Clients communicate with HiveServer2 over a JDBC/ODBC connection. Can have multiple HiverServer2 daemons for HA managed by zookeeper. HiveServer2 has embedded metastore (using derby to cache meta info) apart from external MetastoreDB.
Display all config parameters using set command
hive> set # displays all config parameters
hive> show databases;
hive> use xademo;
hive> show tables;
hive> show create table customer_details;
The following default hive property indicates that the meta-data is stored in MySQL by default:
javax.jdo.option.ConnectionURL=jdbc:mysql://localhost/hive?createDatabaseIfNotExist=true
See Also: Spark SQL which uses Hive for metastore and frontend.
1.3.3 PIG¶
Pig platform includes an execution environment and a scripting language (Pig Latin) used to analyzeHadoop data sets. Its compiler translates Pig Latin into sequences of MapReduce programs.
Sometimes it is easier to write PIG script compared to Hive SQL (when job involves some sequential steps). Sometimes it is easier to write SQL than PIG script. Example:
select * from X order by Y limit 10
There is no way you can efficiently execute above query using PIG script without sorting the entire data!!! (sometimes it is impossible to do that due to this being inefficient. A hand coded Map/Reduce can do the optimization well. An Apache-Sparc program also can do this efficiently ???
NOTE: MapReduce jobs can store into HBASE, but HBASE does not trigger MapReduce Jobs.
1.3.4 Ambari¶
Apache Ambari is a web-based tool for provisioning, managing, and monitoring Apache Hadoop clusters. Ambari leverages open source tools such as Ganglia for metrics collection and Nagios for system alerting (e.g. sending emails when a node goes down, remaining disk space is low, etc). Use puppet for installation.
Supports blueprints as templates.
1.3.5 Hue¶
Hadoop User Interface Tool was initial Hadoop UI based cluster management tool from Cloudera. Written on Python/Django. Now a days Hortonwork’s Ambari works well and overall better. Some features like HBase browser are there in Hue only.
1.3.6 Apache zookeeper¶
Configuration repository – used by cluster managers. Nodes are accessed with file-system like paths. Each node has associated data limited to max 1 MB.
Single point of failure is prevented by having the client also the list of zookeeper servers. i.e. the zookeeper url is like srv1,srv2,srv3. So the failover is automatically handled by client itself! As long as a majority of the servers are available, the ZooKeeper service will be available.
Read requests processed locally. Write requests are forwarded to other ZooKeeper servers and go through consensus. Thus, the throughput of read requests scales with the number of servers and the throughput of write requests decreases with the number of servers.
Projects using zookeeper: * HDFS 2.0 name node (i.e. Resource Manager) uses zookeeper for HA. The first HDFS version 1.0 did not use zookeeper. * HBASE Master Server Daemon uses zookeeper which is co-located along with HDFS Namenode. * Mesos - Cluster management tool uses zoo keeper to detect partitioning of nodes. * YARN - MapReduce 2.0 Resource scheduler uses zoo keeper to detect partitioning and config sharing *
For distributed cron job locking, you can use zookeeper: * http://zookeeper.apache.org/doc/r3.2.2/recipes.html * https://aws.amazon.com/blogs/compute/scheduling-ssh-jobs-using-aws-lambda/ * Chronos: Fault tolerant job scheduler for Mesos - https://mesos.github.io/chronos/
1.3.7 Apache FLUME¶
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data.
Typically to transfer file to HDFS, you do:
$ hadoop fs -put /path of the required file /path in HDFS where to save the file
But above command does not stream continuos data.
But flume enables streaming of log data into HDFS.
1.3.8 Scribe¶
Scribe is a log collection framework over Thrift (language independent protocol definition framework), built and open sourced by Facebook. Another alternative to Flume to stream log data to HDFS. Flume is more popular. Note: Even Kafka can be used to stream data into Hadoop as an alternative.
1.3.9 Cassandra¶
An open source distributed database management system and is a columner database. At twitter, they use HBASE for OLAP and Cassandra for OLTP. Written in Java inspired by Amazon Dynamo. It provides eventual consistency. Twitter migrated from MySQL to Casssandra.
It is not as performant as Redis/Memcache (written in C) which is key/value based database. Cassandra provides HiveQL interface to access data but Redis does not. If data is inherently Key/Value or requires high consistency then Redis is better.
Querying by key, or key range (secondary indices are also available). You can write triggers in Java.
Apache Spark, Cassandra, Kafka is latest industry standard stack.
1.3.10 FlockDB¶
An open source distributed, fault-tolerant graph database for managing data at webscale.
1.3.11 Apache Thrift¶
Thrift is an interface definition language and binary communication protocol[1] that is used to define and create services for numerous languages. Thrift includes a complete stack for creating clients and servers.
1.3.12 Apache Sqoop¶
Apache Sqoop(TM) is a tool to transfer data between Hadoop and RDBMS (and other structured databases).
1.3.13 Apache Drill¶
Apache Drill is an open source, low-latency query engine for big data:
- Interactive SQL analytics at petabyte scale.
- Ability to discover schemas on-the-fly
- Drill is a pioneer in delivering self-service data exploration capabilities
- Data stored in multiple formats in files or NoSQL databases.
- Also provides Rest API
- Drill is fully ANSI SQL compliant and integrates seamlessly with visualization tools.
1.3.14 Apache Impala¶
SQL interface to HBASE. Originally developed by Cloudera.
Apache Impala is the open source, native analytic database for Apache Hadoop. Impala is shipped by Cloudera, MapR, Oracle, and Amazon.
Provies HiveQL compatible query language. Faster querying of HDFS data without typical Map/Reduce overhead that comes with HiveSQL. Note: Unlike Hive, it does not convert the query into MR job.
1.3.15 Stinger¶
Another Impala alternative (incubating) ??
1.3.16 Nimbus¶
A toolkit installed with cluster for management of services. Used with Apache Storm mainly.
1.3.17 KNOX¶
Knox is a system which provides single point of authentication for hadoop services.
1.3.18 Kafka¶
See Also: http://www.slideshare.net/ToddPalino/kafka-at-scale-multitier-architectures
- Apache Kafka is a distributed, publish-subscribe using topics messaging infrastructure.
- Designed for realtime streaming and high throughput and reliable.
- Originally from LinkedIn, made opensource in 2011.
- High availability comes from using Zookeeper.
- Does not follow JMS Standards, neither uses JMS APIs.
- Supports both queue and topic semantics:
- Queue semantics says first-in-first-out and processing should be in same order.
- Realizes that different topics can be processed in parallel, but within same topic, the messages should be processed in same sequence.
- Typical JMS kind of processing where messages are distributed round-robin may result in message processing out-of-order if some consumers are slower.
- Partitions and assigns the set of topics to each partition for consumers to consume. One partition will not have more than 1 Kafka broker to process. i.e. If there is only one Kafka broker, it may end up processing all partitions. However single partition will never be serviced by 2 brokers. Brokers deliver to consumers.
- Uses TCP for communication using binary content.
- Producers find Kafka broker address by consulting Zookeeper.
- Consumers periodically updates the last processed message offset number into Zookeeper for recovery. After crash, consumer can consult with Zookeeper to know last processed message (or use mmapped file or both).
- Consumers track last processed message offset. (This is unlike JMS)
- Partitioning logic based on topics is user controllable (with default being some hashing).
- Use of topics enables to visualize call graphs better.
- In linkedIn the config is about 1100 Kafka brokers,32000 topics, 350K partitions. i.e. 30 topics/Broker, 10 Partitions/Topic. Capable of handling 10.5 Million msgs per second.
- Investigate different design patterns on priority based handling of messages depending on topcs .... TODO.
- Mirror maker cluster of high priority topics makes it easier to restart cluster and catchup.
- Producers and consumers can send audit messages which can be persisted/analysed later.
- Sequential disk access is very fast - Kafka persistence designed to leverage this. Each message is persisted.
Kafka components¶
Partitions : A partition, or more specifically topic partition, is the unit of parallelism in Kafka.
Replicas : In Kafka, replication is implemented at the partition level.
Brokers : A typical Kafka installation (or cluster) consists of one or more servers,
hosting partitions belonging to different topics.
Zookeeper serves as the metadata store for Kafka cluster. Zookeeper is a required component.
1.3.19 Zookeeper¶
Simple highly available distributed configuration manager. Zookeeper clients url looks like: zk://host1:port1,host2:port2,host3:port3 So clients will connect to any one which is available. Zookeeper servers are in odd number to elect quorum leader: e.g. 3, 5, 7, etc.
It maintains a file system like name space where each node is associated with some values. Clients can subscribe to watch specific nodes to get notified. Can use heartbeats to keep track of live nodes associated with nodes in zk tree.
Other controllers/servers can make use of zookeeper to elect leaders - Zookeeper itself does not elect leader for arbitrary external cluster of servers. Multiple clusters of servers can use single Zookeeper installation to elect their group leaders.
Use Cases:
- Kafka cluster makes use of zookeeper for HA configuration sharing and to elect controller.
- Hbase uses zookeeper to elect HMaster which co-ordinates region servers
- HDFS 2.0 uses it for Resource Manager for HA.
- MesOS has master and couple of standby Masters and MesOs agent daemons. Zookeeper is used by both clients, masters, agents to detect the latest master and automatic takeover of the master by the standby master if master goes down.
1.3.20 Amazon Kinesis¶
Hosted message service – Kafka alternative.
1.3.21 Apache Storm¶
Apache Storm is a distributed computation framework written predominantly in the Clojure programming language. It is apache spark alternative.
1.3.22 Akka¶
Akka is a toolkit and runtime for building highly concurrent, distributed, and resilient message-driven applications on the JVM. Apache/spark was written in Scala which makes use of Akka for it’s implementation.
1.3.23 Storm-Kafka Pipelines¶
In a Storm topology, a Spout is the source of data streams (i.e. Kafka) and a Bolt holds the business logic (i.e. Storm) for analyzing and processing those streams. i.e. Kafka acts more like data stream router and Storm is more like processor.
See: http://hortonworks.com/blog/storm-kafka-together-real-time-data-refinery/
Also See: Storm Blueprints by Taylor Goetz
1.3.24 Spark Vs Storm¶
See http://www.slideshare.net/ptgoetz/apache-storm-vs-spark-streaming
One key difference between Spark vs STORM is that Spark performs Data-Parallel computations while Storm performs Task-Parallel computations. Spark streaming supports micro-batching where as storm is record-at-a-time. Should compare with Storm-Trident which supports micro batching.
1.3.25 MongoDB¶
Documented oriented, NoSQL database written in C++. Uses Sharding (horizontal partitioning across server instances). Uses BSON. Highly scalable, Document oriented. Master/Slave replication, auto failover. Can configure N replica sets.
Pluggable storage engine. By default uses mmap to file as storage engine.
Terminologies
-------------------------------------------
RDBMS MongoDB
-------------------------------------------
Table Collection
Row Document
Join Embedding and Linking
Can run arbitrary javascript functions server side. Easy to add columns.
1.3.26 REDIS¶
Distributed in-memory key/value datastructure store written in C. High performance. It supports data structures such as strings, hashes, lists, sets, etc. Master-slave replication, automatic failover.
It is used as database cache and message broker. It provides publish/subscribe messaging features as well, but may not be as sophisticated as other dedicated message brokers (like RabbitMQ, Kafka, etc).
Solr using Apache Lucene -
1.3.27 CouchDB¶
Written in Erlang. Document Oriented. Supports WebAPI.
1.3.28 Riak¶
A key/value store database
1.3.29 Voldemort¶
A key/value store database from LinkedIn. Big hash table like. Out of CAP theorem, it is AP system (sacrificing consistency, if need be).
1.3.30 AWS Lambda¶
AWS Lambda is an event-driven, serverless computing platform provided by Amazon. The purpose of Lambda, as compared to AWS EC2, is to simplify building smaller, on-demand applications that are responsive to events and new information. AWS targets starting a Lambda instance within milliseconds of an event. Node.js, Python and Java are all officially supported as of 2016, and other languages can be supported via call-outs.
AWS Lambda offers the perfect middle ground between IaaS and PaaS. It also effectively counters the growing threat of containers to its business by simplifying the task of running code in the cloud. It is Amazon’s way of delivering a microservices framework far ahead of its competitors.
Currently, there are three ways of running code in AWS cloud: Amazon EC2, Amazon ECS, and AWS Elastic Beanstalk. EC2 is a full-blown IaaS while ECS is the hosted container environment. Finally, Elastic Beanstalk is a PaaS layer. AWS Lambda forms the fourth service with the capability to execute code in the cloud. But it is unique in a sense that it is at the intersection of EC2, ECS, and Elastic Beanstalk.
1.3.31 Amazon’s ECS (EC2 Container Service), aka Docker on AWS¶
A container instance can be any EC2 instance, running any distro (Amazon Linux, Ubuntu, CoreOS)
It just needs two extra software components:
the Docker daemon, the AWS ECS agent. The ECS agent is open source (Apache license). You can check the ECS agent repo on github.
There is no additional cost: you pay only for the EC2 resources; it only works on VPC
Your containers will run on your EC2 instances (a bit like for Elastic Beanstalk, if you are familiar with that)
A task is an instanciation of a task definition. In other words, that will be a group of related, running containers.
- Build image using whatever you want.
- Push image to registry.
- Create JSON file describing your task definition.
- Register this task definition with ECS.
- Make sure that your cluster has enough resources.
- Start a new task from the task definition.
1.4 Docker¶
See:
- https://blog.codeship.com/docker-machine-compose-and-swarm-how-they-work-together/
- https://github.com/wsargent/docker-cheat-sheet
Software level container using docker engine to isolate applications from one another. They share same OS but have separate /bin and /lib and application binaries, completely isolated. Each container can have independent TCP ports binding to same tcp port number without conflict. You can choose to do port forwarding of specific ports from container to host.
Lighter than virtual machines.
Developers can get going quickly by starting with one of the 13,000+ apps available on Docker Hub.
- An instance of a docker image is called container.
- You can see all your images with docker images whereas you can see your running containers with docker ps (and you can see all containers with docker ps -a).
- Image is a set of layers.
Docker originally used LinuX Containers (LXC), but later switched to runC (formerly known as libcontainer), which runs in the same operating system as its host. This allows it to share a lot of the host operating system resources. Also, it uses a layered filesystem (AuFS) and manages networking. Inspired by FreeBSD Jails.
AuFS is a layered file system, so you can have a read only part and a write part which are merged together. One could have the common parts of the operating system as read only (and shared amongst all of your containers) and then give each container its own mount for writing. So you could easily run thousands of containers on a host.
Some commands:
apt-get install docker.io
# Use debian as the container OS just for kicks (it's also smaller than ubuntu)
docker run -i -t debian /bin/bash
# will present you after some downloading with the following root shell in the container. Yay.
root@482791e6cc1a:
# now uname still gives ubuntu, because this is a container and not a true VM..
docker pull ubuntu:14.10 # Remember to specify version; otherwise it will download all versions!!!
service docker.io restart # Restarts docker engine.
# docker run creates a container, configures it and runs a command in it. Every run creates a new container.
# So a lot of containers will be generated. Observe them with docker ps -a.
# You will want to periodically clean up all the cruft with docker rm.
# When you need to reconfigure a container, you need to "commit" it. That creates an image out of the container,
# that can then be reconfigured with a new run command. There is no other way.
# For a container, especially with networking configured, expect to do a lot of commits and runs.
In general all data or logs in the container, are transient. To persist certain mount points, do the following:
# Map data to persist in, via -v
root@host:~# mkdir /usr/local/test
root@host:~# docker run -i -t -v /usr/local/test:/tmp/test debian /bin/bash
root@ec08690b183a:/# mount
/dev/disk/by-uuid/77fb49ed-b208-4709-9a68-9cd6e6b3d7f4 on /tmp/test type ext4 (rw,relatime,errors=remount-ro,data=ordered)
root@ec08690b183a:/# touch /tmp/test/FROM_CONTAINER
root@ec08690b183a:/# ^P^Q # Come out of shell, but run docker shell in background.
root@ubuntu-14:~# ls /usr/local/test/
The container stops, when the shell stops
Use CTRL-P CTRL-Q to step out of the container shell and keep the shell running. Reattach with docker attach.
docker run -i -t -p 127.0.0.1:8082:80 debian /bin/bash
root@26e40f043fbb: apt-get update
...
root@26e40f043fbb: apt-get install apache2
root@26e40f043fbb: apachectl start
root@26e40f043fbb: ^P^Q
root@26e40f043fbb:/#
root@ubuntu-14:~# telnet 127.0.0.1 8082
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'
GET /
...
root@ubuntu-14:~# docker attach 26e40f043fbb
root@26e40f043fbb:
The container is a different container, even if run with the same parameters again
root@host: docker run -i -t -p 127.0.0.1:8081:80 debian /bin/bash
root@9f716f2329eb:/# apachectl start
bash: apachectl: command not found
The container's previous processes are gone after start
root@host:~# docker ps -a
root@host:~# docker start 26e40f043fbb
# Getting rid of unused images
docker rmi $(docker images --filter dangling=true --quiet)
See Also: https://www.ctl.io/developers/blog/post/docker-networking-rules/
1.4.1 Docker container orchestration Tools¶
Google Kubernetes¶
Kubernetes just reached 1.0, has ~9k+ GH stars, and 400+ contributors (as of this posting). It also runs everywhere (AWS, GCP, Azure, on Mesosphere, bare metal), can be hosted (on GKE) and has significant third party contributors (CoreOS, RedHat).
You can get started running on Kubernetes in a single command:
kubectl run nginx --image=nginx --replicas=5
Kubernetes uses flannel, has its own load balancer,uses etcd, uses a CLI, API and configurations that are not the same as Docker engine. So it comes at a cost, especially that it is a pain to install and configure. You will also spend more time learning about it, since its philosophy is different from Docker. But once everything is set up, Kubernetes is a very good technology with lots of features.
Kubernetes is:
- Google Style of Cluster management tool with scheduling capability. Inspired by Google’s internal Borg tool.
- Containers aware - Offers ‘Pods’ as abstraction for set of containers
- Creates some virtual internal IP interfaces (i.e. virtual internal subnets) to create an illusion like echo container like a separate machine (routable). It uses Flannel for that.
- Uses etcd for distributed config store for cluster (which comes by default on CoreOS, must be installed on others)
- Easier to install isolated applications inside a container without port conflicts (as compared to mesos for example)
- kubernetes comes with standard scheduler where as Mesos comes with pluggable scheduler like Marathon. You can even use Kubernetes as your scheduler with MesOS.
- Kubernetes focuses on providing multiple isolation env with-in each computer in a cluster where as Mesos focuses on combining multiple computers to provide virtual giant computer of resources for computing frameworks. You can combine them both if you wish.
Docker Swarm¶
Docker Swarm, is easy to install and use and now it is built-in Docker. It has its own service discovery and same CLI as Docker and it can be integrated easily with Docker in production environment.
Mesos/Marathon¶
Mesos is proven to scale and effectively powers Twitter’s entire infrastructure. Marathon is a framework for orchestration, that can also handle docker.
Another option is to go with Kubernetes which can run as a framework on top of Mesos.
1.4.2 Controlling Network under Docker¶
To host webserver behind NAT, check http://portforward.com to see tips on configuring your specific router.
See Also: * http://superuser.com/questions/121435/is-it-possible-to-host-a-web-server-from-behind-a-nat * http://stackoverflow.com/questions/26539727/giving-a-docker-container-a-routable-ip-address
1.5 Cloud Stack¶
Out of box platform:
Triton, Racher, and some close sourced: Docker UCP, Tectonic, DCOS, ContainerX
-------------------------------------------------------------------------------------------
Clustering & App Orchestration:
Mesos/Marathon, Docker Swarm, Google Kubernetes, Nomad, Aurora, ECS
-------------------------------------------------------------------------------------------
Service Discovery: etcd, consul, zookeeper
-------------------------------------------------------------------------------------------
Storage Mgmt: | Networking: | Exec: | Image: | Repo Server:
Flocker, Portworx | CNM, CNI | Docker, rkt, | ACI, | Docker Hub,
| Flannel, etc| mesos | Docker Image | CoreOS Quay
-------------------------------------------------------------------------------------------
Host OS : Ubuntu, Debian, CoreOS, etc.
-------------------------------------------------------------------------------------------
Cloud Resource:AWS, Azure, GCE, OpenStack, etc. | Infra Orchestrate:
| Terraform, Heat
-------------------------------------------------------------------------------------------
1.7 Some Bigdata Companies¶
Some framework or software providers on big data ...
1.7.1 Cloudera¶
Oldest hadoop support company. Cloudera is just as good as Hortonworks but some of it components like Cloudera Manager are not open source.
1.7.2 Hortonworks¶
More modern and 100% opensource hadoop support company.
1.7.3 MapR¶
MapR is another hadoop/bigdata support provider and also provides high quality free trainings.
1.7.4 GCP - Google Computing Platform / Engine¶
Google data processing tools include Google Cloud Pub/Sub, Google Cloud Dataflow, Google BigQuery, and Google Cloud Dataproc. They are usually more easier to use and less number of choices (so less confusing) of tools for specific use case. Spotify (online music company) is moving to google platform.
AWS has “three” queuing systems, “two” storage solutions with different API’s and different quirks. Google just has one and its nails the use cases for queuing and storage. This is not currently true. Google has: Datastore, Cloud SQL, Bigtable, BigQuery and Cloud Storage [1]. Each is intended for a different use case, as are Amazon’s offerings.
1.8 Cluster Managers¶
- YARN - Mainly for Hadoop, but generic.
- Mesos - Meant to be generic.
- Myriad is meant for scheduling of YARN jobs via Mesos.
- Kubernetes - Low level cluster of modern OS which is container aware
1.10 Hortonworks Data Platform - HDP¶
1.10.1 SERVICES PROVIDED BY THE HDP SANDBOX and HTTP TCP PORTS¶
This is the default TCP ports used by standard HDP Sandbox distribution
Service URL
Sandbox Welcome Page http://host:8888
Ambari Dashboard http://host:8080
Ambari Welcome http://host:8080/views/ADMIN_VIEW/2.2.1.0/INSTANCE/#/
Hive User View http://host:8080/#/main/views/HIVE/1.0.0/AUTO_HIVE_INSTANCE
Pig User View http://host:8080/#/main/views/PIG/1.0.0/Pig
File User View http://host:8080/#/main/views/FILES/1.0.0/Files
SSH Web Client http://host:4200
Hadoop Configuration http://host:50070/dfshealth.html http://host:50070/explorer.html
THE FOLLOWING TABLE CONTAINS LOGIN CREDENTIALS:
Service User Password
Ambari maria_dev maria_dev
Ambari admin admin thavaadmin
Linux OS root hadoop/thavamuni
1.11 Amazon Offerings¶
EC2 - Running machine on cloud. IaaS - Infrastructure as Service. Google Compute Engine is google alternative.
EMR - Elastic Map Reduce - Amazon EMR is a managed cluster platform for running big data frameworks, such as Apache Hadoop and Apache Spark.
ECS - EC2 Container service aka Docker on AWS
* Your containers will run on your EC2 instances (a bit like for Elastic Beanstalk, if you are familiar with that) * there is no additional cost: you pay only for the EC2 resources * it only works on VPC ?? there is no console dashboard yet; you have to use the CLI or API * for now, you can only start containers from public images hosted on the Docker Hub * Allows you to easily run applications on a managed cluster of Amazon EC2 instances. * EC2 instance (container instance) should run docker daemon and AWS agent.
Elastic Beanstack.
AWS Elastic Beanstalk is a PaaS (Platform as a Service). Google alternative is Google App Engine.
Users to create applications and deploy on AWS Beanstack.
Application can use AWS services, including EC2, S3, SNS, CloudWatch, autoscaling, and Elastic Load Balancers, etc.
There is no additional charge for Elastic Beanstalk. You pay only for the underlying AWS resources.
- Example: Web application ::
- web app deployed automatically gets URL myapp.elasticbeanstack.com.
- Using Amazon Route 53 DNS, this URL maps to elastic load balancer IP address.
Different container types (stacks) are supported. e.g. Apache Tomcat/Linux/Apache webserver; etc.
Can use predefined docker images as containers.
Lambda - AWS Lambda is a compute service. You provide the code (Java, Python, etc) to run. You can’t directly access/configure the EC2 that it is running on. Provides auto management of infrastructure. If you need to control the EC2, then use Elastic Beanstack. Typically can be invoked from AWS SDK API calls made from HTTP request handler or event handler for changes to S3, DynamoDB etc. Use the built-in CloudWatch monitoring of your Lambda functions to view and optimize request latencies.
S3 - Scalable Storage in the Cloud.
Cloudfront - It is a content delivery network (CDN) to cache web media using global proxy servers. Video Streaming. Site acceleration.
Amazon Elastic File System (EFS) provides scalable file storage for use with Amazon EC2.
Amazon Glacier is an extremely low-cost storage service.
Amazon RDS - Provides RDBMS as service. Can choose MySQL/Oracle/Postgres/Amazon Aurora. Competitors include Google Cloud SQL, Rackspace Cloud Databases, Azure SQL, HP Cloud, ClearDB, etc.
Amazon DynamoDB is a fully managed NoSQL database service. It was originally intended as high available key-value store, but now supports multiple columns, secondary indexes, etc. Can be compared to Google Bigtable and Hadoop HBASE. Does synchronous replication.
Redshift - Amazon Redshift is postgres compatible RDBMS for datawarehousing and analytics.
ElastiCache is a Amazon web service for in-memory cache in cloud. aka Redis or memcached in Amazon.
CloudWatch: Monitor Resources and Applications
CloudFormation: Create and Manage Resources with Templates
OpsWorks Automate Operations with Chef
Trusted Advisor Optimize Performance and Security
SQS - Simple Message Queue Service
- SNS - Simple notification service - push notifications to mobile device users, email recipients or even send
messages to other distributed services such as SQS, AWS Lambda or HTTP endpoints.
Kinesis - Realtime data streaming
1.12 Apache Spark¶
1.12.1 Overview¶
- Distributed in-memory cluster computing framework.
- Main advantage comes from using efficient execution engine (like Tez vastly improved by project Tungsten) without having to use MapReduce.
- Easier to chain a custom sequence of map and reduce operations with better control.
- It is micro-batching architecture for high throughput.
- Spark Streaming module provides real-time processing like Apache Storm.
- Storage could be HDFS, Cassandra, S3, etc. It can even support local file system but cluster must be single node stand-alone mode only.
- Spark SQL provides SQL interface to spark engine. It reuses Hive frontend and metastore, but provides much better performance than Hive (or Impala from Cloudera). Usually used with HDFS storage as it makes use of Hive, however it can support storage in S3, etc as well.
- RDD - Resilient, Distributed, Dataset - Fault tolerant and immutable
- Uses RDD (2011) => DataFrame(2013) => Dataset(2015)
- Supports inputs: Text files or Hadoop InputFormat or SequenceFiles
- RDD operations can be expressed as DAG : Directed Acyclic Graph
Typical Architecture:
------ +-----------> Spark-Streaming ---------------->+----------------+
Kafka >===| | Cassandra DB |===> Realtime/Batch View
------ +-----------> HDFS --> Spark-Processing ------>+----------------+
- Sparc Streaming consumes data from input stream like Kafka (called DStream) using micro-batching vs Regular Spark Processing consumes data from HDFS or local file.
1.12.2 What is Resilient Distributed Datasets (RDDs)?¶
See http://spark.apache.org/docs/latest/programming-guide.html#overview
Spark revolves around the concept of a resilient distributed dataset (RDD), which is a fault-tolerant collection of elements that can be operated on in parallel. There are two ways to create RDDs: parallelizing an existing collection in your driver program, or referencing a dataset in an external storage system, such as a shared filesystem, HDFS, HBase, or any data source offering a Hadoop InputFormat
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName(appName).setMaster(master) # Use appName="local", master="local" for local testing.
#
# Possible values of master parameter:
# local - Use local single worker
# local[5] - Set local 5 worker thereads.
# local[*] - Set as many workers as local cores.
# spark://HOST:PORT - connect to a Spark standalone cluster;
# mesos://HOST:PORT - connect to a Mesos cluster;
#
sc = SparkContext(conf=conf)
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data)
# distData = sc.parallelize(data, 10) # we say: 10 partitions.
# distData.reduce(lambda a, b: a + b) # Computes sum of all elements.
# lines = sc.textFile("data.txt") # Default parallelization parameter is newline delimiter.
# # This is RDD, but just a pointer, not loaded into memory yet.
lineLengths = lines.map(lambda s: len(s)) # Lazy evaluation. This is again just specification. No action.
totalLength = lineLengths.reduce(lambda a, b: a + b) # This triggers action.
# Note that some operations,such as join,are only available on RDDs of key-value pairs.
Serializing/unserializing a collection of key, value pairs could not be easier:
>>> rdd = sc.parallelize(range(1, 4)).map(lambda x: (x, "a" * x ))
>>> rdd.saveAsSequenceFile("path/to/file")
>>> sorted(sc.sequenceFile("path/to/file").collect())
[(1, u'a'), (2, u'aa'), (3, u'aaa')]
RDDs support two types of operations: transformations, which create a new dataset from an existing one, and actions, which return a value to the driver program after running a computation on the dataset. For example, map is a transformation that passes each dataset element through a function and returns a new RDD representing the results. On the other hand, reduce is an action that aggregates all the elements of the RDD using some function and returns the final result to the driver program (although there is also a parallel reduceByKey that returns a distributed dataset).
Caveats about closure:
counter = 0
rdd = sc.parallelize(data) # say data = [ 10, 20, 30 ]
# Wrong: Don't do this!!
def increment_counter(x):
global counter
counter += x
rdd.foreach(increment_counter) # increment_counter(10); increment_counter(20); etc invoked.
print("Counter value: ", counter) # Global variable modified. Results undefined when executed under cluster.
Solution: Don't use globals or use Accumulator pattern.
Also See: http://spark.apache.org/examples.html
1.12.3 DataFrame¶
Some examples from pyspark shell
# Search through error msgs in log files.
textFile = sc.textFile("hdfs://...")
# Creates a DataFrame having a single column named "line"
df = textFile.map(lambda r: Row(r)).toDF(["line"])
errors = df.filter(col("line").like("%ERROR%"))
# Counts all the errors
errors.count()
# Counts errors mentioning MySQL
errors.filter(col("line").like("%MySQL%")).count()
# Fetches the MySQL errors as an array of strings
errors.filter(col("line").like("%MySQL%")).collect()
# Simple data operations
url = \
"jdbc:mysql://yourIP:yourPort/test?user=yourUsername;password=yourPassword"
df = sqlContext \
.read \
.format("jdbc") \
.option("url", url) \
.option("dbtable", "people") \
.load()
# Looks the schema of this DataFrame.
df.printSchema()
# Counts people by age
countsByAge = df.groupBy("age").count()
countsByAge.show()
# Saves countsByAge to S3 in the JSON format.
countsByAge.write.format("json").save("s3a://...")
However, you can go from a DataFrame to an RDD via its rdd method, and you can go from an RDD to a DataFrame (if the RDD is in a tabular format) via the toDF method
1.12.4 Using UDF with Dataframe¶
from pyspark.sql.types import BooleanType
less_ten = udf(lambda s: s < 10, BooleanType())
# Initialize data as a list of some arbitrary tuples.
dataDF = sqlContext.createDataFrame(data, ('last_name', 'first_name', 'ssn', 'occupation', 'age') )
lambdaDF = dataDF.filter(less_ten(dataDF.age))
# Note: dataDF.age is Column type, not an integer constant.
lambdaDF.show()
lambdaDF.count()
1.12.5 How to install spark cluster ?¶
Spark cluster can be of any one of these types:
- Spark Standalone - Built-in cluster manager. Easier to setup and manage. Less Complex. Probably more suited for Sparc streaming where much of processing requires only compute node resource and data is replicated in-memory, so data co-location is not an issue.
- MesOS - Generic Cluster manager. RDDs may encode data location info (i.e. HDFS file), should assign compute nodes co-located to data nodes. Need more investigation how to properly setup. You can also use adapter Myriad to interact with external YARN scheduler. Multiple instances of Spark can share single MesOS cluster.
- YARN - More suitable if the input data is HDFS. Allocation of compute nodes co-lcated with data is easier.
Using Sparc Standalone cluster manager means using the scripts to start master and slaves manually. When the slaves are started they connect to master using startup options – that is how the masters know the slaves exist:
./sbin/start-master.sh
Once started, the master will print out a spark://HOST:PORT URL for itself, which you can use to connect workers to it, or pass as the master argument to SparkContext. You can also find this URL on the master’s web UI, which is http://localhost:8080 by default.
Similarly, you can start one or more workers and connect them to the master via:
./sbin/start-slave.sh <master-spark-URL>
Once you have started a worker, look at the master’s web UI (http://localhost:8080 by default). You should see the new node listed there, along with its number of CPUs and memory (minus one gigabyte left for the OS).
To run an application on the Spark cluster, simply pass the spark://IP:PORT URL of the master as to the SparkContext constructor.
To run an interactive Spark shell against the cluster, run the following command:
./bin/spark-shell --master spark://IP:PORT
You can also pass an option –total-executor-cores <numCores> to control the number of cores that spark-shell uses on the cluster.
For running with MESOS, See http://spark.apache.org/docs/latest/running-on-mesos.html
To submit job to spark cluster, use spark-submit script:
# Run application locally on localhost on 8 cores
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[8] /path/to/examples.jar 100
# Run on a Spark standalone cluster in client deploy mode
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://207.184.161.138:7077
--executor-memory 20G --total-executor-cores 100 /path/to/examples.jar 1000
See http://spark.apache.org/docs/latest/submitting-applications.html
If you are connecting to mysql from spark-shell, do this:
# spark-shell --jars mysql-connector.jar
1.12.6 What processes run in cluster ?¶
http://spark.apache.org/docs/latest/cluster-overview.html
- There is
- Driver program which contains sparkContext
- Any cluster manager: spark bundled standalone cluster manager, Hadoop YARN or Apache Mesos.
- Executor java process per Worker node. (separate JVM process).
1.12.7 What is Spark Streaming ?¶
See original white paper: https://www2.eecs.berkeley.edu/Pubs/TechRpts/2012/EECS-2012-259.pdf
Uses micro-batching where data from t0-t1 is constructed as a DStream and processed.
Easier monitoring and interactive queries
Spark Streaming can read data from HDFS, Flume, Kafka, Twitter and ZeroMQ. You can also define your own custom data sources.
Data can be ingested from many sources like Kafka, Flume, Kinesis, or TCP sockets, and can be processed using complex algorithms expressed with high-level functions like map, reduce, join and window.
Finally, processed data can be pushed out to filesystems, databases, and live dashboards. In fact, you can apply Spark’s machine learning and graph processing algorithms on data streams.
See https://databricks.com/blog/2015/01/15/improved-driver-fault-tolerance-and-zero-data-loss-in-spark-streaming.html for better fault tolerance with spark streaming using Write-ahead-log.
Spark driver runs receivers as threads and divides input into blocks in memory. These in-memory blocks are also replicated (to other machines or same process ??). Every batch interval the driver, launches tasks to process the blocks.
How Stream code is different from regular processing ?
# API is almost same except the initialization of input stream. # spark-shell --driver-memory 1G scala > val ssc = new StreamingContext(sc, Seconds(2)) val lines = ssc.socketTextStream("localhost",8585,MEMORY_ONLY) val wordsFlatMap = lines.flatMap(_.split(" ")) .... .... # Compare this with lines = sc.textFile("data.txt") # Default parallelization parameter is newline delimiter. OR data = [1, 2, 3, 4, 5] distData = sc.parallelize(data) # In regular processing the size of input is known unlike in streaming.
1.12.8 pyspark Shell Usage¶
Following things are pre-imported:
- dbutils package
- sparkContext object sc : - res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@6ad51e9c (scala) - sc: <__main__.RemoteContext at 0x7ff0bfb18a10>
- from pyspark.sql.context.HiveContext import sql # object.
- import pyspark.sql.context.HiveContext as sqlContext
- from pyspark.sql.context.HiveContext import table # object
Note: databricks uses dbfs - Databricks File system which is not opensource. Similar to HDFS. Do not bother to dig much into this.
1.12.9 Scala Shell Usage¶
To execute external shell commands do
scala> import sys.process._
scala> "ls -l" !
... output ...
result: Int = 0
scala> val result = "ls -al" ! # Stores 0 to result.
scala> val result = "ls -al" !! # Store output string into result.
result: String = " .... output ... "
val result = "ps auxw" #| "grep http" #| "wc -l" ! # #! is scala's pipeline operator.
# Other pipeline operators supported by scala shell: #< #> #>> #&& #!!
1.12.10 Spark shell same as Scala interpreter ?¶
This is a scala shell with spark libraries already loadedd.
Use spark-shell (which is a scala shell) only for incremental development/testing. For running application, package application as .jar file and use spark-submit for deployment.
1.12.12 Common mistakes in using spark ?¶
https://www.youtube.com/watch?v=WyfHUNnMutg
Also See: https://github.com/hadooparchitecturebook/hadoop-arch-book
- An example resource distribution of 16 nodes of 64GB each with 9? cores each:
- average 3 executors per node of 5 cores each per executor: total 17 executors of 19 GB memory each.
No spark shuffle block can be greater than 2 GB !!! Solution: increase the number of partitions and decrease the skew, randomize the keyname.
Common Mistakes and Solutions:
In Spark SQL, Increase spark.sql.shuffle.partitions
In regular spark application, use rdd.repartition() or rdd.coalesce()
- To address skew, common techniques:
- Salting (keys) - Randomize the key name. (2 stage aggregation)
- Filter out the skewed data and handle them separately (as another job?) Isolation Salting
- Isolation Map Joins - Filter out the specific condition of join.
Approx 128MB per partition works.
Shuffles are to be avoided
Prefer RduceByKey over GroupByKey
Avoid Cartesians
Examine your Spark DAG execution plan.
Use TreeReduce instead of Reduce.
Use Complex Types for Reduce Object – not limited to just tuple. You can use hash map, set, whatever.
1.12.13 Advantages of Spark Over MapReduce (MR) ?¶
While MR has just two steps (map and reduce), DAG can have multiple levels that can form a tree structure. Say if you want to execute a SQL query, DAG is more flexible with more functions like map, filter, union etc. Also DAG execution is faster as in case of Apache Tez that succeeds MR due to intermediate results not being written to disk.
Users can control two other aspects of RDDs: persistence and partitioning. Users can indicate which RDDs they will reuse and choose a storage strategy for them (e.g., in-memory storage). They can also ask that an RDD’s elements be partitioned across machines based on a key in each record. This is useful for placement optimizations, such as ensuring that two datasets that will be joined together are hash-partitioned in the same way.
Spark exposes RDDs through a language-integrated API similar to DryadLINQ[31] and FlumeJava [8], where each dataset is represented as an object and transformations are invoked using methods on these objects.
1.12.15 How to improve fault tolerance of unreliable data source (which can not resend data) ?¶
Common Pattern: Back unreliable data with Kafka for 100% durability. (Kafka has built-in data backup capability ???)
1.12.16 How to attach to / examine existing RDDs in Sparc ?¶
In Python you can simply try to filter globals by type:
def list_rdds():
from pyspark import RDD
return [k for (k, v) in globals().items() if isinstance(v, RDD)]
list_rdds()
# []
rdd = sc.parallelize([])
list_rdds()
# ['rdd']
In Scala REPL you should be able to use $intp.definedTerms / $intp.typeOfTerm in a similar way.
1.12.17 How to examine/print RDD ?¶
If you want to view the content of a RDD, one way is to use collect():
myRDD.collect().foreach(println)
That’s not a good idea, though, when the RDD has billions of lines. Use take() to take just a few to print out:
myRDD.take(n).foreach(println)
1.13 CAP Theorem¶
1.13.1 Overview¶
You should pick any two of Consistency, Availability and Partition Tolerance:
- Consistency - No inconsistent ‘sequential’ reads. i.e. A writes 1 then 2 to location X, B can not read 2 then 1.
- Availability - The data store must be available for both read and write. Measure of redundancy against few disk failures as well.
- Partition Tolerance - If there is network partition, will the system continue to work ? When there is no tolerance, whole system will shutdown after detecting partition. Or one (smaller) partition may be shutdown (partial tolerance). or both partitions will be allowed to operate independently (fully tolerant but at the cost of consistency).
In big data NoSQL environment, consistency guarantee is very expensive since few node failures and partitioning is quite common. Note that single node hardware/OS/software failure is also equivalent to partitioning. Hence AP systems are popular compromising on Consistency by providing ‘Eventual Consistency’.
Zookeeper favours consistency and disables the smaller partition from operating. (Intelligent partition handling, but technically not fully partition tolerant!!!).
HDFS also chooses consistency. Writes are more expensive than reads. Decent availability till 3 datanodes failure. In case of partitioning, nodes available from namenode side survive, others rendered useless. Partial partition tolerance.
1.13.2 CA Sytems¶
All RDBMS systems.
1.13.3 CP Systems¶
Gives up availability to be consistent but usually works well when there are few nodes down / Partitioning. Note: One can argue CA and CP are almost same since CP sacrifices Availability only during partitioning.
Examples include:
- Hbase, BigTable (All column oriented)
- MongoDB (Master-Slave replicated data), Couchbase (Document oriented)
- BerkeleyDB, Redis, MemcacheDB (Always consistent) (Key-value) Losing a node will mean data loss for that hashed partition, but there is no incorrect read/writes happening.
1.13.4 AP Systems¶
Gives up partial consistency (eventually consistent, may be) in order to be available (or for lower latency).
Examples Include:
- Cassandra, Amazon Dynamo (column oriented)
- Voldemort(linkedin, key-value)
- SimpleDB, CouchDB (Document oriented)
1.13.5 Conclusion¶
Daniel suggests PACELC : In case of partitioning, choose between Availability and Consistency, Else choose between lower-latency and consistency.
i.e. You don’t give up consistency just for availability, sometimes you do just for lower latency. The system could be PA-EL (gives up consistency) or PA-EC (gives up consistency only when there is partitioning not otherwise), etc.
See Also:
1.14 Hive File Formats¶
1.14.1 Overview¶
Hive files can be stored in any one of following formats:
- TEXTFILE - Plain text, one line per record.
- SEQUENCEFILE - sequence of compressed binary row objects. Useful as intermediate storage.
- RCFile - Record Columnar File - Columnar format. Very efficient for large tables.
- ORC - Optimized Record Columnar format - Columnar format - for better complex types support, compression, indexing.
The default format can be set as follows from Hive:
hive> SET hive.default.fileformat=Orc
1.14.2 ORC¶
ORC is a self-describing type-aware columnar file format designed for Hadoop workloads.
It is optimized for large streaming reads and with integrated support for finding required rows fast.
ORC supports the complete set of types in Hive, including the complex types: structs, lists, maps, and unions
Note that csv files are not self-describing.
Following Hive SQL prepares hive data warehouse repository to store a new table in ORC format:
create table my_orc_table( col1 String, col2 bigint) stored as orc
To dump orc file, use: hive –orcfiledump <location-of-orc-file>
From Apache Spark, you can:
Create RDD using Hive SQL : val my_rdd = hiveContext.sql(“select * from my_orc_table”) - Lazy action.
Store RDD directly into any ORC file - my_rdd.saveAsOrcFile(“my_orc_file”) - Triggers action ?
Store RDD into hive temporary table (caches to prevent recomputing RDD later): my_rdd.registerTempTable(“my_temp_table”) - Lazy hint to cache later.
- Load ORC file to into Hive Table:
hiveContext.sql(“load data inpath ‘my_orc_file’ into table my_orc_table”)
1.15 Using Vagrant¶
1.15.1 Vagrant for Single Ubuntu instance on VirtualBox¶
Also See: * http://code.tutsplus.com/tutorials/vagrant-what-why-and-how–net-26500
Synopsis:
$ gem install vagrant
$ mkdir -p ~/Vagrant/test
$ cd ~/Vagrant/test
$ vagrant box add precise32 http://files.vagrantup.com/precise32.box
# You see here the argument "precise32" which is a nickname for the URL.
# You can now create an instance, which will download this .box.
$ vagrant init precise32
$ vagrant up
# It will now be running. Easy! If you want to get into this instance, via SSH, use this command:
$ vagrant ssh
$ vagrant list-commands
There is Vagrantfile where you can configure:
- network address and portforwarding
- shared folders
- Provisioning scripts: single inline bash scripting or puppet manifest files.
- Pyrocms is a famous manifests repository: http://github.com/pyrocms/devops-puppet
Here is an example Vagrantfile:
# -*- mode: ruby -*-
# vi: set ft=ruby :
Vagrant::Config.run do |config|
config.vm.box = "precise32"
config.vm.box_url = "http://files.vagrantup.com/precise32.box"
# Assign this VM to a host-only network IP, allowing you to access it
# via the IP. Host-only networks can talk to the host machine as well as
# any other machines on the same network, but cannot be accessed (through this
# network interface) by any external networks.
config.vm.network :hostonly, "192.168.33.10"
# Set the default project share to use nfs
config.vm.share_folder("v-web", "/vagrant/www", "./www", :nfs => true)
config.vm.share_folder("v-db", "/vagrant/db", "./db", :nfs => true)
# Forward a port from the guest to the host, which allows for outside
# computers to access the VM, whereas host only networking does not.
config.vm.forward_port 80, 8080
# Set the Timezone to something useful
config.vm.provision :shell, :inline => "echo \"Europe/London\" | sudo tee /etc/timezone && dpkg-reconfigure --frontend noninteractive tzdata"
# Update the server
config.vm.provision :shell, :inline => "apt-get update --fix-missing"
# Enable Puppet
config.vm.provision :puppet do |puppet|
puppet.facter = { "fqdn" => "local.pyrocms", "hostname" => "www" }
puppet.manifests_path = "puppet/manifests"
puppet.manifest_file = "ubuntu-apache2-pgsql-php5.pp"
puppet.module_path = "puppet/modules"
end
end
Here is an example puppet manifests file for installing apache and configure the default parameters. It refers to predefined puppets module ‘apache’
include apache
$docroot = '/vagrant/www/pyrocms/'
$db_location = "/vagrant/db/pyrocms.sqlite"
# Apache setup
class {'apache::php': }
apache::vhost { 'local.pyrocms':
priority => '20',
port => '80',
docroot => $docroot,
configure_firewall => false,
}
a2mod { 'rewrite': ensure => present; }
The manifests are OS independent. The module has been written to capture OS specific installation details.
1.15.2 Using Core-OS and Vagrant to create Cluster¶
For creating core-OS cluster using vagrant, See: https://coreos.com/os/docs/latest/booting-on-vagrant.html :
- core-OS allows to provide system config parameters information in cloud-config format using file user-data.
- cloud-config involves getting unique ID: wget https://discovery.etcd.io/new
- The number of machines information is provided in config.rb file.
- The Vagrant, user-data, config.rb files provide the config information.
- The coreos implementation of cloud-init is coreos-cloudinit.
- The same config file can be used to bootstrap CoreOS on Vagrant, Amazon EC2, Google Compute Engine (GCE), and more
- fleetctl command can control machines in cluster and schedule jobs to them.
- etcdctl command can populate distributed data store to dynamically set configuration parameters.
- You now have a powerful little cluster on your laptop, complete with job scheduling, a distributed data store and a self-updating operating system
Synopsis
$ git clone https://github.com/coreos/coreos-vagrant.git
$ cd coreos-vagrant
$ curl https://discovery.etcd.io/new?size=3 # produces output file containing. e.g. https://discovery.etcd.io/e850b12eb5569631101bf5ac7db2e22f
# The e85...22f value is called token.
$ cp user-data.sample user-data
$ vi user-data # Edit file to provide config in cloud-config format. Replace the <token> with the token value.
# The values of $public_ipv4 and $private_ipv4 are derived using Vagrant file config.
$ vi config.rb # Set $num_instances = 3
$ vagrant up
$ vagrant status
--- running status of 3 machines --
$ ssh-add ~/.vagrant.d/insecure_private_key
$ vagrant ssh core-01 -- -A # Connects to single machine in cluster
# Your Vagrantfile should copy your cloud-config file to /var/lib/coreos-vagrant/vagrantfile-user-data
$ ls -l /var/lib/coreos-vagrant/vagrantfile-user-data
$ fleetctl list-machines
# Lists machine-ids and status
$ cat > hello-fleet.service
[Service]
ExecStart=/usr/bin/bash -c "while true; do echo 'Hello Fleet'; sleep 1; done"
$ fleetctl start hello-fleet.service
Job hello-fleet.service scheduled to 517d1c7d.../172.17.8.101
$ etcdctl set first-etcd-key "Hello World" # Set a config parameter in one machine. Reflects in all cluster...
$ fleetctl ssh cb35b356 etcdctl get first-etcd-key
Hello World
See Also:
- https://github.com/weaveworks/guides/blob/master/spark-coreos-vagrant.md
- https://github.com/zilin/coreos-spark
- https://community.hortonworks.com/articles/39156/setup-hortonworks-data-platform-using-vagrant-virt.html
- https://github.com/vangj/vagrant-hadoop-2.4.1-spark-1.0.1
- http://hortonworks.com/blog/building-hadoop-vm-quickly-ambari-vagrant/
1.17 FAQ¶
1.17.1 How Big is bigdata ?¶
NYSE generates 1 TB data per day. Facebook generates 20 TB per day. The internet archive stores around 20TB per month !!!
- Volume - A lot. In TBs or PBs
- Velocity - Fast growing. Streaming. Time sensitive
- Variety - XML, Text, PDF, unstructured, many formats
- Veracity - Lot of imprecise data. May be incomplete. Anamolies. etc.
1.17.2 What exactly MapReduce does ?¶
See O’Reily MapReduce Design Patterns.
See following figure: Image Source: http://stackoverflow.com/questions/22141631/what-is-the-purpose-of-shuffling-and-sorting-phase-in-the-reducer-in-map-reduce :
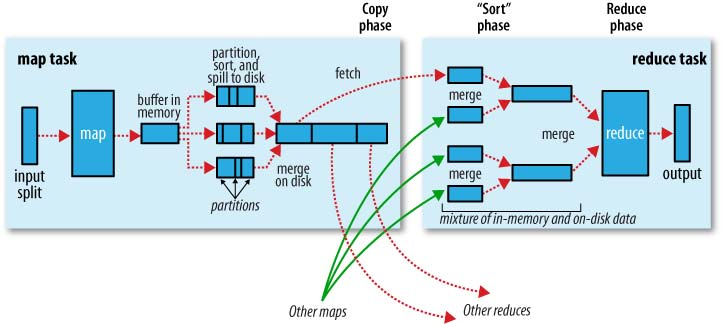
- Mappers : Load Data from HDFS, Filter, (more filtering it does, better processing at datanode itself),
- transform (into keyvalue pairs, for example). Outputs key, value pairs (only???).
- Each map task in Hadoop is broken into the following phases:
- record reader, mapper, combiner (local reducer), and partitioner. The output of the map tasks, called the intermediate keys and values, are sent to the reducers.
- The reduce tasks are broken into the following phases:
- shuffle, sort, reducer, and output format. The nodes in which the map tasks run are optimally on the nodes in which the data rests.
The record reader translates an input split generated by input format into records.
In the mapper, user-provided code is executed on each key/value pair from the record reader to produce zero or more new key/value pairs, called the intermediate pairs
The combiner, an optional localized reducer, can group data in the map phase.
The reduce task starts with the shuffle and sort step. The shuffle is nothing but the process of receiving/aggregating data from different mappers and assign it to the relevant reduce task for the corresponding key. This step takes the output files written by all of the partitioners and downloads them to the local machine in which the reducer is running. Not customizable except providing Comparator object to tell how to sort.
The reducer takes the grouped data as input and runs a reduce function once per key grouping. The function is passed the key and an iterator over all of the values associated with that key. A wide range of processing can happen in this function, as in many of our patterns. The data can be aggregated, filtered, and combined in a number of ways. Once the reduce function is done, it sends zero or more key/value pair to the final step, the output format. Like the map function, the reduce function will change from job to job since it is a core piece of logic in the solution. The output format translates the final key/value pair from the reduce function and writes it out to a file by a record writer. By default, it will separate the key and value with a tab and separate records with a newline character.
1.17.3 What is Map ?¶
* Input (Key, Value)
* Output: List(Key , Value ) # For each input pair you can produce 0 or more list of output pairs. Key is comparable.
* Projections, Filtering, Transformation
Example: Input: [ (1, line1), (2, line2), ... ] and output: [ (word1, N1), (word2, N2), ... ]
1.17.4 What is shuffle ?¶
* Input: List(Key, Value)
* Output: Sort(Partition(List(Key, List(Value ))))
1.17.5 What is Reduce ?¶
* Input: List(Key, List(Value))
* Output: List(Key, Value )
* Aggregation
1.17.6 When does reduce task start in Hadoop ?¶
It is customizable. If there are many jobs running, delaying the reduce job until all mappers finish is useful. Otherwise starting asap is better.
Depending on the problem, reducer may require completion of the entire mappers to finish or can do incremental work. http://stackoverflow.com/questions/11672676/when-do-reduce-tasks-start-in-hadoop
Set mapreduce.job.reduce.slowstart.completedmaps from 0.0 to 1.0 in mapred-site.xml.
1.17.7 How does hadoop process records split across block boundaries ?¶
Mappers don’t have to communicate with each other.
There is fileSplit (e.g. 1GB), blocks (e.g. 64MB), RecordReader, LineRecordReader. If the split is not the first split, the first line (in the first block) is always ignored since it relies on the previous split handler to read the last line after the last block.
1.17.8 Can you write non-Java scripting for Map/Reduce ?¶
Yes. There is support for using scripting with Hadoop Map Reduce stages
bin/hadoop jar hadoop-streaming.jar -input in-files -output out-dir -mapper mapper.sh -reducer reducer.sh
mapper.sh: sed -e s/ /n/g | grep .
reducer.sh: uniq -c | awk {print $2 t $1}
1.17.9 Some cheap solutions for building a Hadoop or any cluster for computing ?¶
- Install one of famous hadoop distributions yourself on your machines or EC2 machines: - CDH - Cloudera - Hortonworks HDP - MapR Hadoop Distribution
- Use Amazon EMR - Elastic MapReduce Cluster with data in S3 - which uses MapR distribution.
- Use Google Cloud Platform
- Use Hadoop-as-a-Service providers (Qubole and Altiscale , etc)
- Use databricks platform on AWS. The supported notebooks/netbook interface provides much better cluster manager for doing spark based computing.
- Use CoreOS general purpose low level cluster just for running arbitrary jobs.
- Microsoft HD insights ???
- Just load the data into many S3 buckets and use any computing platfrom like Spark. (I dont like S3 – too slow)
- Other less knowns ... xplenty.com, zillabyte, etc
1.17.10 What is best for Data Analytics: R or Python ?¶
You can have both using rpy2 library of python. See http://rpy.sourceforge.net/rpy2/doc-2.1/html/introduction.html
1.17.11 How does network bandwidth compare with disk access ?¶
Reference Links¶
http://www.slideshare.net/ikewu83/dean-keynoteladis2009-4885081
Some reference times from 2011
L1 cache reference 0.5 ns Branch mispredict 5 ns L2 cache reference 7 ns Mutex lock/unlock 100 ns (25) Main memory reference 100 ns Compress 1K bytes with Zippy 10,000 ns (3,000) Send 2K bytes over 1 Gbps network 20,000 ns Read 1 MB sequentially from memory 250,000 ns Round trip within same datacenter 500,000 ns (.5 ms) Disk seek 10,000,000 ns (10 ms) (SSD Disk around 0.1ms ?) Read 1 MB sequentially from network 10,000,000 ns Read 1 MB sequentially from disk 30,000,000 ns (30 ms) Send packet CA->Netherlands->CA 150,000,000 ns (150 ms)
SAN - Storage area network. SAN is nothing but a high speed network that makes connections between storage devices and servers. SAN is a more sophisticated NAS device that allows others computers to treat its partitions like a DAS. Has multiple network ports to provide speed boost. More complex to configure, so more error prone. Provides raw block level storage access. Interface is either Fiber channel or iSCSI or Infini band.
NAS - Network attached storage. Typically, has IP address and runs custom OS as file server. Shares files over the network. Not storage device over the network.
DAS - Directly attached storage. Highest speed, but can not share the storage with other computers (without additional software support). For bigdata also DAS is preferred since this can horizontally scale out. For exclusive access of disk (eg. RDBMS storage), DAS should be preferred. Note: Disk recovery in NAS is more simpler compared to DAS ?
Connecting cables¶
- Fiber Channel :Uses Fiber protocol. Cable can even be copper. Can multiplex IO and network using same adapter.
Point-to-point between host and storage array. Speed in range of 1.6 GB/sec or 3.2 GB/sec or 6.4G GB/sec.
Thunderbolt
SAS - Serially Attached SCSI (300 MB/sec or 600 MB/sec or 1.2GB/sec speed for 1/2/3rd generation)
SATA I, SATA II, SATA 3.0 (6 Gbps)
SCSI
- Ethernet (1 or 10 or 100 Gbps) or 100 MB/sec or 1 GB/sec or 10 GB/sec )
- Storage device may be connected thru ethernet using iSCSI protocol. Used to carry SCSI traffic over IP networks. Exposes blocklevel access over network compared to NFS which exposes file level access.
USB
Note: DRAM can transfer speed at 20 GB/sec
Network Types¶
1 Gbps network port will push about 125MB / second of data. This is about same as single IDE disk read access rate.
10 Gbps network port can push about 1GB / sec data. This is about same as 10 RAID disks attached which can read about 1 GB/sec data.
- 100 Gbps network port can push about 10 GB/sec. Current datacenters do use this much capacity.
This is about 100 disks each with 100MB/sec read speed or 25 disks with each 400MB/sec read speed. i.e. This network can withstand around 25 computers on network each bumping around 400MB/sec data !!! It is just half the speed of single DRAM memory channel !!!
1.17.12 How to use netcat to test TCP and UDP connections ?¶
Following tips will be useful in setting up and troubleshooting cluster machines.
netcat and nc are aliases.
Usage
$ netcat localhost 80 # TCP connect like telnet on port 80
$ netcat -u localhost 80 # You can send UDP packet instead of TCP.
$ netcat -z -v localhost 1-1000 # Scan all ports upto 1000. nmap tool may be even better.
$ netcat -l 4444 # Listen on TCP port 4444. Act like a server. It will exit after 1 session.
# You can interact with connection using stdin.
$ netcat -l 4444 > received_file # Receive file through netcat. Wait till some one sends it.
$ netcat localhost 4444 < sendfile # Send file through netcat.
$ netcat -l 8888 < index.html # Act like simple webserver, which dumps html as soon as it receives a connection.
# http://localhost:8888 will show this html.
$ while true; do nc -l 8888 < index.html; done # Keep serving the same page again and again.
$ nc -lk 8888 < index.html # It does the same thing as above. Listen in a loop.
$ echo -n "GET / HTTP/1.0\r\n\r\n" | nc host.example.com 80 # Get http page from server.
$ nc localhost 25 << EOF # Act like smtp client
HELO host.example.com
MAIL FROM: <user@host.example.com>
RCPT TO: <user2@host.example.com>
DATA
Body of email.
.
QUIT
EOF
See Also: man nc
1.17.13 Compare Oracle RAC vs Hadoop HW Topology¶
Oracle RAC: Database servers running in different machines share large disk arrays connected by SAN. (i.e. highspeed network switches and Fiber Channel cables). Hadoop uses many computers each has DAS (directly attached storage device).
1.17.14 What are the types of NoSQL Databases ?¶
- Column Oriented - Can support dynamic number of columns on the fly - Eg: HBASE, Cassandra, ...
- Document Oriented - MongoDB, CouchDB, ...
- Key-Value - Redis, Voldemort (linkedin), MemcacheDB, ...
- Graph - Neo4j, Jena, FlockDB (twitter), ...
1.17.15 What is the best SQL engine for Hadoop ?¶
There is no shortage of SQL on Hadoop offerings, and each Hadoop distributor seems to have its preferred flavor.
The list begins with the original SQL-on-Hadoop engine, Apache Hive, which was created at Facebook and is now backed by Hortonworks with its Stinger initiative.
In 2012, Cloudera rolled out the first release of Apache Impala to great fanfare, while lately MapR has been pushing the schema-less bounds of SQL querying with Apache Drill, which is based on Google’s Dremel.
But the prospective SQL-on-Hadoop user may also want to check out other offerings, including those from mega-vendors like: BigSQL (backed by IBM), Big Data SQL (backed by Oracle), and Vertica SQL on Hadoop (backed by Hewlett-Packard). Others in the race include Presto (created by Facebook, now backed by Teradata), Vortex (backed by Actian), Apache HAWQ (backed by Pivotal) and Apache Phoenix. Last but not least is Spark SQL, the SQL-enabling component of Apache Spark that is quickly gaining momentum. Also Microsoft Polybase.