Common Generative AI Interview Questions
Owner: Aishwarya Nr
Generative Models
- What is the difference between generative and discriminative models?
- Answer:
- Generative models, such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs), are designed to generate new data samples by understanding and capturing the underlying data distribution. Discriminative models, on the other hand, focus on distinguishing between different classes or categories within the data.
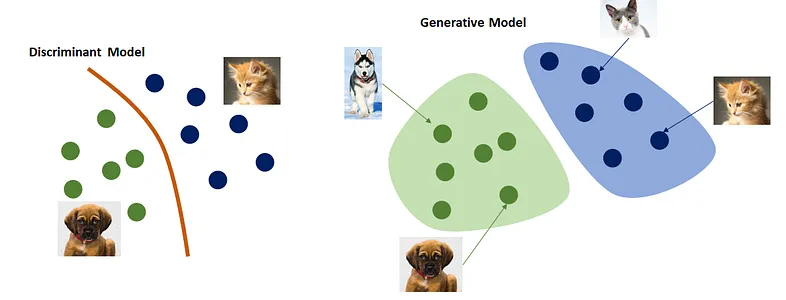 Image Source: https://medium.com/@jordi299/about-generative-and-discriminative-models-d8958b67ad32
Image Source: https://medium.com/@jordi299/about-generative-and-discriminative-models-d8958b67ad32
- Generative models, such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs), are designed to generate new data samples by understanding and capturing the underlying data distribution. Discriminative models, on the other hand, focus on distinguishing between different classes or categories within the data.
- Describe the architecture of a Generative Adversarial Network and how the generator and discriminator interact during training.
- Answer:
A Generative Adversarial Network comprises a generator and a discriminator. The generator produces synthetic data, attempting to mimic real data, while the discriminator evaluates the authenticity of the generated samples. During training, the generator and discriminator engage in a dynamic interplay, each striving to outperform the other. The generator aims to create more realistic data, and the discriminator seeks to improve its ability to differentiate between real and generated samples.
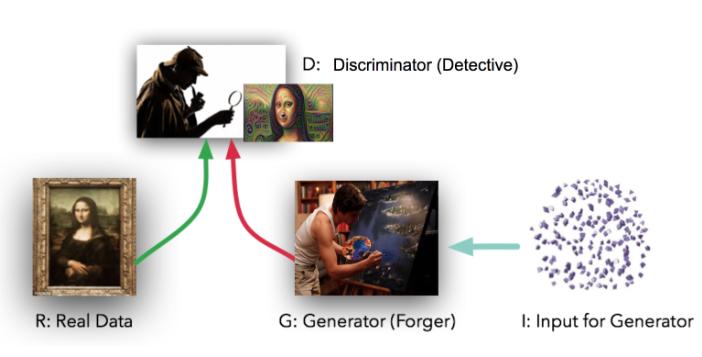 Image Source: https://climate.com/tech-at-climate-corp/gans-disease-identification-model/
Image Source: https://climate.com/tech-at-climate-corp/gans-disease-identification-model/
- Explain the concept of a Variational Autoencoder (VAE) and how it incorporates latent variables into its architecture.
- Answer:
A Variational Autoencoder (VAE) is a type of neural network architecture used for unsupervised learning of latent representations of data. It consists of an encoder and a decoder network.
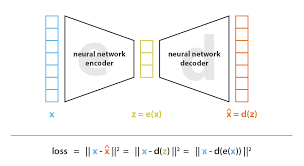 Image source: https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
The encoder takes input data and maps it to a probability distribution in a latent space. Instead of directly producing a single latent vector, the encoder outputs parameters of a probability distribution, typically Gaussian, representing the uncertainty in the latent representation. This stochastic process allows for sampling from the latent space.
The decoder takes these sampled latent vectors and reconstructs the input data. During training, the VAE aims to minimize the reconstruction error between the input data and the decoded output, while also minimizing the discrepancy between the learned latent distribution and a pre-defined prior distribution, often a standard Gaussian.
By incorporating latent variables into its architecture, the VAE learns a compact and continuous representation of the input data in the latent space. This enables meaningful interpolation and generation of new data samples by sampling from the learned latent distribution. Additionally, the probabilistic nature of the VAE's latent space allows for uncertainty estimation in the generated outputs.
read this article: https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
Image source: https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
The encoder takes input data and maps it to a probability distribution in a latent space. Instead of directly producing a single latent vector, the encoder outputs parameters of a probability distribution, typically Gaussian, representing the uncertainty in the latent representation. This stochastic process allows for sampling from the latent space.
The decoder takes these sampled latent vectors and reconstructs the input data. During training, the VAE aims to minimize the reconstruction error between the input data and the decoded output, while also minimizing the discrepancy between the learned latent distribution and a pre-defined prior distribution, often a standard Gaussian.
By incorporating latent variables into its architecture, the VAE learns a compact and continuous representation of the input data in the latent space. This enables meaningful interpolation and generation of new data samples by sampling from the learned latent distribution. Additionally, the probabilistic nature of the VAE's latent space allows for uncertainty estimation in the generated outputs.
read this article: https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
- How do conditional generative models differ from unconditional ones? Provide an example scenario where a conditional approach is beneficial.
- Answer:
Conditional generative models differ from unconditional ones by considering additional information or conditions during the generation process. In unconditional generative models, such as vanilla GANs or VAEs, the model learns to generate samples solely based on the underlying data distribution. However, in conditional generative models, the generation process is conditioned on additional input variables or labels.
For example, in the context of image generation, an unconditional generative model might learn to generate various types of images without any specific constraints. On the other hand, a conditional generative model could be trained to generate images of specific categories, such as generating images of different breeds of dogs based on input labels specifying the breed.
A scenario where a conditional approach is beneficial is in tasks where precise control over the generated outputs is required or when generating samples belonging to specific categories or conditions. For instance:
- In image-to-image translation tasks, where the goal is to convert images from one domain to another (e.g., converting images from day to night), a conditional approach allows the model to learn the mapping between input and output domains based on paired data.
- In text-to-image synthesis, given a textual description, a conditional generative model can generate corresponding images that match the description, enabling applications like generating images from textual prompts.
- What is mode collapse in the context of GANs, and what strategies can be employed to address it during training?
- Answer:
Mode collapse in the context of Generative Adversarial Networks (GANs) refers to a situation where the generator produces limited diversity in generated samples, often sticking to a few modes or patterns in the data distribution. Instead of capturing the full richness of the data distribution, the generator might only learn to generate samples that belong to a subset of the possible modes, resulting in repetitive or homogeneous outputs.
Several strategies can be employed to address mode collapse during training:
- Architectural Modifications: Adjusting the architecture of the GAN can help mitigate mode collapse. This might involve increasing the capacity of the generator and discriminator networks, introducing skip connections, or employing more complex network architectures such as deep convolutional GANs (DCGANs) or progressive growing GANs (PGGANs).
- Mini-Batch Discrimination: This technique encourages the generator to produce more diverse samples by penalizing mode collapse. By computing statistics across multiple samples in a mini-batch, the discriminator can identify mode collapse and provide feedback to the generator to encourage diversity in the generated samples.
- Diverse Training Data: Ensuring that the training dataset contains diverse samples from the target distribution can help prevent mode collapse. If the training data is highly skewed or lacks diversity, the generator may struggle to capture the full complexity of the data distribution.
- Regularization Techniques: Techniques such as weight regularization, dropout, and spectral normalization can be used to regularize the training of the GAN, making it more resistant to mode collapse. These techniques help prevent overfitting and encourage the learning of more diverse features.
- Dynamic Learning Rates: Adjusting the learning rates of the generator and discriminator dynamically during training can help stabilize the training process and prevent mode collapse. Techniques such as using learning rate schedules or adaptive learning rate algorithms can be effective in this regard.
- Ensemble Methods: Training multiple GANs with different initializations or architectures and combining their outputs using ensemble methods can help alleviate mode collapse. By leveraging the diversity of multiple generators, ensemble methods can produce more varied and realistic generated samples.
- How does overfitting manifest in generative models, and what techniques can be used to prevent it during training?
- Answer:
Overfitting in generative models occurs when the model memorizes the training data rather than learning the underlying data distribution, resulting in poor generalization to new, unseen data. Overfitting can manifest in various ways in generative models:
- Mode Collapse: One common manifestation of overfitting in generative models is mode collapse, where the generator produces a limited variety of samples, failing to capture the full diversity of the data distribution.
- Poor Generalization: Generative models might generate samples that closely resemble the training data but lack diversity or fail to capture the nuances present in the true data distribution.
- Artifacts or Inconsistencies: Overfitting can lead to the generation of unrealistic or inconsistent samples, such as distorted images, implausible text sequences, or nonsensical outputs.
- Regularization: Regularization techniques such as weight decay, dropout, and batch normalization can help prevent overfitting by imposing constraints on the model's parameters or introducing stochasticity during training.
- Early Stopping: Monitoring the performance of the generative model on a validation set and stopping training when performance begins to deteriorate can prevent overfitting and ensure that the model generalizes well to unseen data.
- Data Augmentation: Increasing the diversity of the training data through techniques like random cropping, rotation, scaling, or adding noise can help prevent overfitting by exposing the model to a wider range of variations in the data distribution.
- Adversarial Training: Adversarial training, where the generator is trained to fool a discriminator that is simultaneously trained to distinguish between real and generated samples, can help prevent mode collapse and encourage the generation of diverse and realistic samples.
- Ensemble Methods: Training multiple generative models with different architectures or initializations and combining their outputs using ensemble methods can help mitigate overfitting by leveraging the diversity of multiple models.
- Cross-Validation: Partitioning the dataset into multiple folds and training the model on different subsets while validating on the remaining data can help prevent overfitting by providing more reliable estimates of the model's performance on unseen data.
- What is gradient clipping, and how does it help in stabilizing the training process of generative models?
- Answer:
Gradient clipping is a technique used during training to limit the magnitude of gradients, typically applied when the gradients exceed a predefined threshold. It is commonly employed in deep learning models, including generative models like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs).
Gradient clipping helps stabilize the training process of generative models in several ways:
- Preventing Exploding Gradients: In deep neural networks, particularly in architectures with deep layers, gradients can sometimes explode during training, leading to numerical instability and hindering convergence. Gradient clipping imposes an upper bound on the gradient values, preventing them from growing too large and causing numerical issues.
- Mitigating Oscillations: During training, gradients can oscillate widely due to the complex interactions between the generator and discriminator (in GANs) or the encoder and decoder (in VAEs). Gradient clipping helps dampen these oscillations by constraining the magnitude of the gradients, leading to smoother and more stable updates to the model parameters.
- Enhancing Convergence: By preventing the gradients from becoming too large or too small, gradient clipping promotes more consistent and predictable updates to the model parameters. This can lead to faster convergence during training, as the model is less likely to encounter extreme gradient values that impede progress.
- Improving Robustness: Gradient clipping can help make the training process more robust to variations in hyperparameters, such as learning rates or batch sizes. It provides an additional safeguard against potential instabilities that may arise due to changes in the training dynamics.
- Discuss strategies for training generative models when the available dataset is limited.
- Answer:
When dealing with limited datasets, training generative models can be challenging due to the potential for overfitting and the difficulty of capturing the full complexity of the underlying data distribution. However, several strategies can be employed to effectively train generative models with limited data:
- Data Augmentation: Augmenting the existing dataset by applying transformations such as rotation, scaling, cropping, or adding noise can increase the diversity of the training data. This helps prevent overfitting and enables the model to learn more robust representations of the data distribution.
- Transfer Learning: Leveraging pre-trained models trained on larger datasets can provide a valuable initialization for the generative model. By fine-tuning the pre-trained model on the limited dataset, the model can adapt its representations to the specific characteristics of the target domain more efficiently.
- Semi-supervised Learning: If a small amount of labeled data is available in addition to the limited dataset, semi-supervised learning techniques can be employed. These techniques leverage both labeled and unlabeled data to improve model performance, often by jointly optimizing a supervised and unsupervised loss function.
- Regularization: Regularization techniques such as weight decay, dropout, and batch normalization can help prevent overfitting by imposing constraints on the model's parameters or introducing stochasticity during training. Regularization encourages the model to learn more generalizable representations of the data.
- Generative Adversarial Networks (GANs) with Progressive Growing: Progressive growing GANs (PGGANs) incrementally increase the resolution of generated images during training, starting from low resolution and gradually adding detail. This allows the model to learn more effectively from limited data by focusing on coarse features before refining finer details.
- Ensemble Methods: Training multiple generative models with different architectures or initializations and combining their outputs using ensemble methods can help mitigate the limitations of a small dataset. Ensemble methods leverage the diversity of multiple models to improve the overall performance and robustness of the generative model.
- Data Synthesis: In cases where the available dataset is extremely limited, data synthesis techniques such as generative adversarial networks (GANs) or variational autoencoders (VAEs) can be used to generate synthetic data samples. These synthetic samples can be combined with the limited real data to augment the training dataset and improve model performance.
- Explain how curriculum learning can be applied in the training of generative models. What advantages does it offer?
- Answer:
Curriculum learning is a training strategy inspired by the way humans learn, where we often start with simpler concepts and gradually move towards more complex ones. This approach can be effectively applied in the training of generative models, a class of AI models designed to generate data similar to some input data, such as images, text, or sound.
To apply curriculum learning in the training of generative models, you would start by organizing the training data into a sequence of subsets, ranging from simpler to more complex examples. The criteria for complexity can vary depending on the task and the data. For instance, in a text generation task, simpler examples could be shorter sentences with common vocabulary, while more complex examples could be longer sentences with intricate structures and diverse vocabulary. In image generation, simpler examples might include images with less detail or fewer objects, progressing to more detailed images with complex scenes.
The training process then begins with the model learning from the simpler subset of data, gradually introducing more complex subsets as the model's performance improves. This incremental approach helps the model to first grasp basic patterns before tackling more challenging ones, mimicking a learning progression that can lead to more efficient and effective learning.
The advantages of applying curriculum learning to the training of generative models include:
- Improved Learning Efficiency: Starting with simpler examples can help the model to quickly learn basic patterns before gradually adapting to more complex ones, potentially speeding up the training process.
- Enhanced Model Performance: By structuring the learning process, the model may achieve better generalization and performance on complex examples, as it has built a solid foundation on simpler tasks.
- Stabilized Training Process: Gradually increasing the complexity of the training data can lead to a more stable training process, reducing the risk of the model getting stuck in poor local minima early in training.
- Reduced Overfitting: By effectively learning general patterns from simpler examples before moving to complex ones, the model might be less prone to overfitting on the training data.
- Describe the concept of learning rate scheduling and its role in optimizing the training process of generative models over time.
- Answer:
Learning rate scheduling is a crucial technique in the optimization of neural networks, including generative models, which involves adjusting the learning rate—the step size used to update the model's weights—over the course of training. The learning rate is a critical hyperparameter that determines how much the model adjusts its weights in response to the estimated error each time it is updated. If the learning rate is too high, the model may overshoot the optimal solution; if it's too low, training may proceed very slowly or stall.
In the context of training generative models, such as Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs), learning rate scheduling can significantly impact the model's ability to learn complex data distributions effectively and efficiently.
Role in Optimizing the Training Process:
- Avoids Overshooting: Early in training, a higher learning rate can help the model quickly converge towards a good solution. However, as training progresses and the model gets closer to the optimal solution, that same high learning rate can cause the model to overshoot the target. Gradually reducing the learning rate helps avoid this problem, allowing the model to fine-tune its parameters more delicately.
- Speeds Up Convergence: Initially using a higher learning rate can accelerate the convergence by allowing larger updates to the weights. This is especially useful in the early phases of training when the model is far from the optimal solution.
- Improves Model Performance: By carefully adjusting the learning rate over time, the model can escape suboptimal local minima or saddle points more efficiently, potentially leading to better overall performance on the generation task.
- Adapts to Training Dynamics: Different phases of training may require different learning rates. For example, in the case of GANs, the balance between the generator and discriminator can vary widely during training. Adaptive learning rate scheduling can help maintain this balance by adjusting the learning rates according to the training dynamics.
- Step Decay: Reducing the learning rate by a factor every few epochs.
- Exponential Decay: Continuously reducing the learning rate exponentially over time.
- Cosine Annealing: Adjusting the learning rate following a cosine function, leading to periodic adjustments that can help in escaping local minima.
- Warm-up Schedules: Gradually increasing the learning rate from a small to a larger value during the initial phase of training, which can help in stabilizing the training of very deep models.
- Compare and contrast the use of L1 and L2 loss functions in the context of generative models. When might one be preferred over the other?
- Answer:
Both loss functions are used to measure the difference between the model's predictions and the actual data, but they do so in distinct ways that affect the model's learning behavior and output characteristics.
L1 Loss (Absolute Loss): The L1 loss function calculates the absolute differences between the predicted values and the actual values. This approach is less sensitive to outliers because it treats all deviations the same, regardless of their magnitude. In the context of generative models, using L1 loss can lead to sparser gradients, which may result in models that are more robust to noise in the input data. Moreover, L1 loss tends to produce results that are less smooth, which might be preferable when sharp transitions or details are desired in the generated outputs, such as in image super-resolution tasks.
L2 Loss (Squared Loss): On the other hand, the L2 loss function computes the square of the differences between the predicted and actual values. This makes it more sensitive to outliers, as larger deviations are penalized more heavily. The use of L2 loss in generative models often results in smoother outcomes because it encourages smaller and more incremental changes in the model's parameters. This characteristic can be beneficial in tasks where the continuity of the output is critical, like generating realistic textures in images.
Preference and Application:
- Preference for L1 Loss: You might prefer L1 loss when the goal is to encourage more robustness to outliers in the dataset or when generating outputs where precise edges and details are important. Its tendency to produce sparser solutions can be particularly useful in applications requiring high detail fidelity, such as in certain types of image processing where sharpness is key.
- Preference for L2 Loss: L2 loss could be the preferred choice when aiming for smoother outputs and when dealing with problems where the Gaussian noise assumption is reasonable. Its sensitivity to outliers makes it suitable for tasks where the emphasis is on minimizing large errors, contributing to smoother and more continuous generative outputs.
- In the context of GANs, what is the purpose of gradient penalties in the loss function? How do they address training instability?
- Answer:
Gradient penalties are a crucial technique designed to enhance the stability and reliability of the training process. GANs consist of two competing networks: a generator, which creates data resembling the target distribution, and a discriminator, which tries to distinguish between real data from the target distribution and fake data produced by the generator. While powerful, GANs are notorious for their training difficulties, including instability, mode collapse, and the vanishing gradient problem.
Purpose of Gradient Penalties:
The primary purpose of introducing gradient penalties into the loss function of GANs is to impose a regularization constraint on the training process. This constraint ensures that the gradients of the discriminator (with respect to its input) do not become too large, which is a common source of instability in GAN training. By penalizing large gradients, these methods encourage smoother decision boundaries from the discriminator, which, in turn, provides more meaningful gradients to the generator during backpropagation. This is crucial for the generator to learn effectively and improve the quality of the generated samples.
Gradient penalties help to enforce a Lipschitz continuity condition on the discriminator function. A function is Lipschitz continuous if there exists a constant such that the function does not change faster than this constant times the change in input. In the context of GANs, ensuring the discriminator adheres to this condition helps in stabilizing training by preventing excessively large updates that can derail the learning process.
Addressing Training Instability:
- Improved Gradient Flow: By penalizing extreme gradients, gradient penalties ensure a more stable gradient flow between the discriminator and the generator. This stability is critical for the generator to learn effectively, as it relies on feedback from the discriminator to adjust its parameters.
- Prevention of Mode Collapse: Mode collapse occurs when the generator produces a limited variety of outputs. Gradient penalties can mitigate this issue by ensuring that the discriminator provides consistent and diversified feedback to the generator, encouraging it to explore a wider range of the data distribution.
- Enhanced Robustness: The regularization effect of gradient penalties makes the training process more robust to hyperparameter settings and initialization, reducing the sensitivity of GANs to these factors and making it easier to achieve convergence.
- Encouraging Smooth Decision Boundaries: By enforcing Lipschitz continuity, gradient penalties encourage the discriminator to form smoother decision boundaries. This can lead to more gradual transitions in the discriminator's judgments, providing the generator with more nuanced gradients for learning to produce high-quality outputs.
- Wasserstein GAN with Gradient Penalty (WGAN-GP): A well-known variant that introduces a gradient penalty term to the loss function to enforce the Lipschitz constraint, significantly improving the stability and quality of the training process.
- Spectral Normalization: Although not a gradient penalty per se, spectral normalization is another technique to control the Lipschitz constant of the discriminator by normalizing its weights, which indirectly affects the gradients and contributes to training stability.
Large Language Models
- Discuss the concept of transfer learning in the context of natural language processing. How do pre-trained language models contribute to various NLP tasks?
- Answer:
Transfer learning typically involves two main phases:
- Pre-training: In this phase, a language model is trained on a large corpus of text data. This training is unsupervised or semi-supervised and aims to learn a general understanding of the language, including its syntax, semantics, and context. Models learn to predict the next word in a sentence, fill in missing words, or even predict words based on their context in a bidirectional manner.
- Fine-tuning: After the pre-training phase, the model is then fine-tuned on a smaller, task-specific dataset. During fine-tuning, the model's parameters are slightly adjusted to specialize in the specific NLP task at hand, such as sentiment analysis, question-answering, or text classification. The idea is that the model retains its general understanding of the language learned during pre-training while adapting to the nuances of the specific task.
- Improved Performance: Pre-trained models have set new benchmarks across various NLP tasks by leveraging their extensive pre-training on diverse language data. This has led to significant improvements in tasks such as text classification, named entity recognition, machine translation, and more.
- Efficiency in Training: By starting with a model that already understands language to a significant degree, researchers and practitioners can achieve high performance on specific tasks with relatively little task-specific data. This drastically reduces the resources and time required to train models from scratch.
- Versatility: The same pre-trained model can be fine-tuned for a wide range of tasks without substantial modifications. This versatility makes pre-trained language models highly valuable across different domains and applications, from healthcare to legal analysis.
- Handling of Contextual Information: Models like BERT (Bidirectional Encoder Representations from Transformers) and its successors (e.g., RoBERTa, GPT-3) are particularly adept at understanding the context of words in a sentence, leading to more nuanced and accurate interpretations of text. This capability is crucial for complex tasks such as sentiment analysis, where the meaning can significantly depend on context.
- Language Understanding: Pre-trained models have advanced the understanding of language nuances, idioms, and complex sentence structures. This has improved machine translation and other tasks requiring deep linguistic insights.
- Highlight the key differences between models like GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers)?
- Answer:
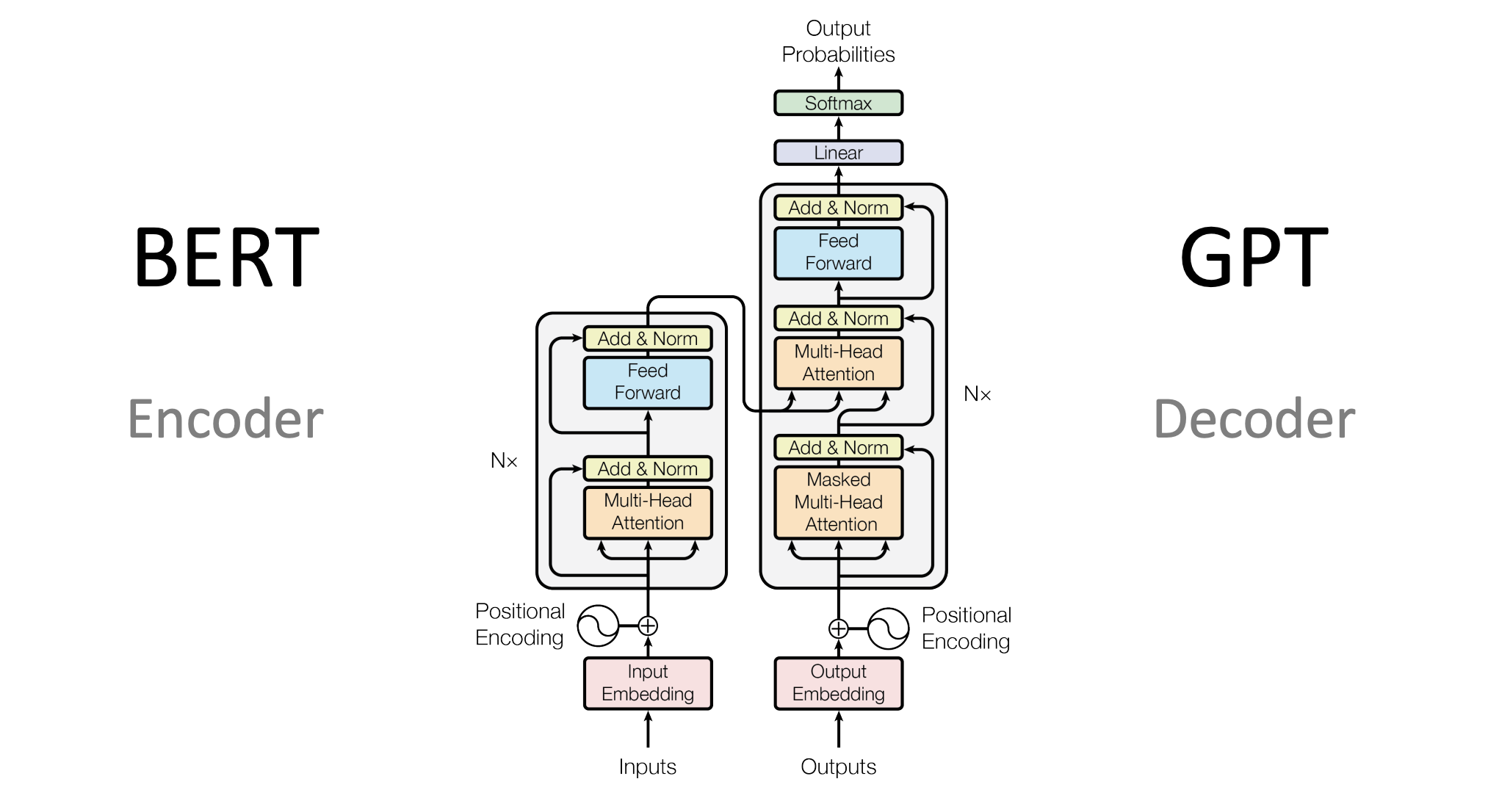 Image Source: https://heidloff.net/article/foundation-models-transformers-bert-and-gpt/
GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers) are two foundational architectures in the field of NLP (Natural Language Processing), each with its unique approach and capabilities. Although both models leverage the Transformer architecture for processing text, they are designed for different purposes and operate in distinct ways.
Image Source: https://heidloff.net/article/foundation-models-transformers-bert-and-gpt/
GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers) are two foundational architectures in the field of NLP (Natural Language Processing), each with its unique approach and capabilities. Although both models leverage the Transformer architecture for processing text, they are designed for different purposes and operate in distinct ways.
Architecture and Training Approach:
- GPT:
- GPT is designed as an autoregressive model that predicts the next word in a sequence given the previous words. Its training is based on the left-to-right context only.
- It is primarily used for generative tasks, where the model generates text based on the input it receives.
- GPT's architecture is a stack of Transformer decoder blocks.
- BERT:
- BERT, in contrast, is designed to understand the context of words in a sentence by considering both left and right contexts (i.e., bidirectionally). It does not predict the next word in a sequence but rather learns word representations that reflect both preceding and following words.
- BERT is pre-trained using two strategies: Masked Language Model (MLM) and Next Sentence Prediction (NSP). MLM involves randomly masking words in a sentence and then predicting them based on their context, while NSP involves predicting whether two sentences logically follow each other.
- BERT's architecture is a stack of Transformer encoder blocks.
Use Cases and Applications:
- GPT:
- Given its generative nature, GPT excels in tasks that require content generation, such as creating text, code, or even poetry. It is also effective in tasks like language translation, text summarization, and question-answering where generating coherent and contextually relevant text is crucial.
- BERT:
- BERT is particularly effective for tasks that require understanding the context and nuances of language, such as sentiment analysis, named entity recognition (NER), and question answering where the model provides answers based on given content rather than generating new content.
Training and Fine-tuning:
- GPT:
- GPT models are trained on a large corpus of text in an unsupervised manner and then fine-tuned for specific tasks by adjusting the model on a smaller, task-specific dataset.
- BERT:
- BERT is also pre-trained on a large text corpus but uses a different set of pre-training objectives. Its fine-tuning process is similar to GPT's, where the pre-trained model is adapted to specific tasks with additional task-specific layers if necessary.
Performance and Efficiency:
- GPT:
- GPT models, especially in their later iterations like GPT-3, have shown remarkable performance in generating human-like text. However, their autoregressive nature can sometimes lead to less efficiency in tasks that require understanding the full context of input text.
- BERT:
- BERT has been a breakthrough in tasks requiring deep understanding of context and relationships within text. Its bidirectional nature allows it to outperform or complement autoregressive models in many such tasks.
- GPT:
- What problems of RNNs do transformer models solve?
- Answer:
Transformer models were designed to overcome several significant limitations associated with Recurrent Neural Networks, including:
- Difficulty with Parallelization: RNNs process data sequentially, which inherently limits the possibility of parallelizing computations. Transformers, by contrast, leverage self-attention mechanisms to process entire sequences simultaneously, drastically improving efficiency and reducing training time.
- Long-Term Dependencies: RNNs, especially in their basic forms, struggle with capturing long-term dependencies due to vanishing and exploding gradient problems. Transformers address this by using self-attention mechanisms that directly compute relationships between all parts of the input sequence, regardless of their distance from each other.
- Scalability: The sequential nature of RNNs also makes them less scalable for processing long sequences, as computational complexity and memory requirements increase linearly with sequence length. Transformers mitigate this issue through more efficient attention mechanisms, although they still face challenges with very long sequences without modifications like sparse attention patterns.
- Why is incorporating relative positional information crucial in transformer models? Discuss scenarios where relative position encoding is particularly beneficial.
- Answer: In transformer models, understanding the sequence's order is essential since the self-attention mechanism treats each input independently of its position in the sequence. Incorporating relative positional information allows transformers to capture the order and proximity of elements, which is crucial for tasks where the meaning depends significantly on the arrangement of components. Relative position encoding is particularly beneficial in: Language Understanding and Generation: The meaning of a sentence can change dramatically based on word order. For example, "The cat chased the mouse" versus "The mouse chased the cat." Sequence-to-Sequence Tasks: In machine translation, maintaining the correct order of words is vital for accurate translations. Similarly, for tasks like text summarization, understanding the relative positions helps in identifying key points and their significance within the text. Time-Series Analysis: When transformers are applied to time-series data, the relative positioning helps the model understand temporal relationships, such as causality and trends over time.
- What challenges arise from the fixed and limited attention span in the vanilla Transformer model? How does this limitation affect the model's ability to capture long-term dependencies?
- Answer The vanilla Transformer model has a fixed attention span, typically limited by the maximum sequence length it can process, which poses challenges in capturing long-term dependencies in extensive texts. This limitation stems from the quadratic complexity of the self-attention mechanism with respect to sequence length, leading to increased computational and memory requirements for longer sequences. This limitation affects the model's ability in several ways: Difficulty in Processing Long Documents: For tasks such as document summarization or long-form question answering, the model may struggle to integrate critical information spread across a large document. Impaired Contextual Understanding: In narrative texts or dialogues where context from early parts influences the meaning of later parts, the model's fixed attention span may prevent it from fully understanding or generating coherent and contextually consistent text.
- Why is naively increasing context length not a straightforward solution for handling longer context in transformer models? What computational and memory challenges does it pose?
- Answer: Naively increasing the context length in transformer models to handle longer contexts is not straightforward due to the self-attention mechanism's quadratic computational and memory complexity with respect to sequence length. This increase in complexity means that doubling the sequence length quadruples the computation and memory needed, leading to: Excessive Computational Costs: Processing longer sequences requires significantly more computing power, slowing down both training and inference times. Memory Constraints: The increased memory demand can exceed the capacity of available hardware, especially GPUs, limiting the feasibility of processing long sequences and scaling models effectively.
- How does self-attention work?
- Answer:
Self-attention is a mechanism that enables models to weigh the importance of different parts of the input data relative to each other. In the context of transformers, it allows every output element to be computed as a weighted sum of a function of all input elements, enabling the model to focus on different parts of the input sequence when performing a specific task. The self-attention mechanism involves three main steps:
Query, Key, and Value Vectors: For each input element, the model generates three vectors—a query vector, a key vector, and a value vector—using learnable weights.
Attention Scores: The model calculates attention scores by performing a dot product between the query vector of one element and the key vector of every other element, followed by a softmax operation to normalize the scores. These scores determine how much focus or "attention" each element should give to every other element in the sequence.
Weighted Sum and Output: The attention scores are used to create a weighted sum of the value vectors, which forms the output for each element. This process allows the model to dynamically prioritize information from different parts of the input sequence based on the
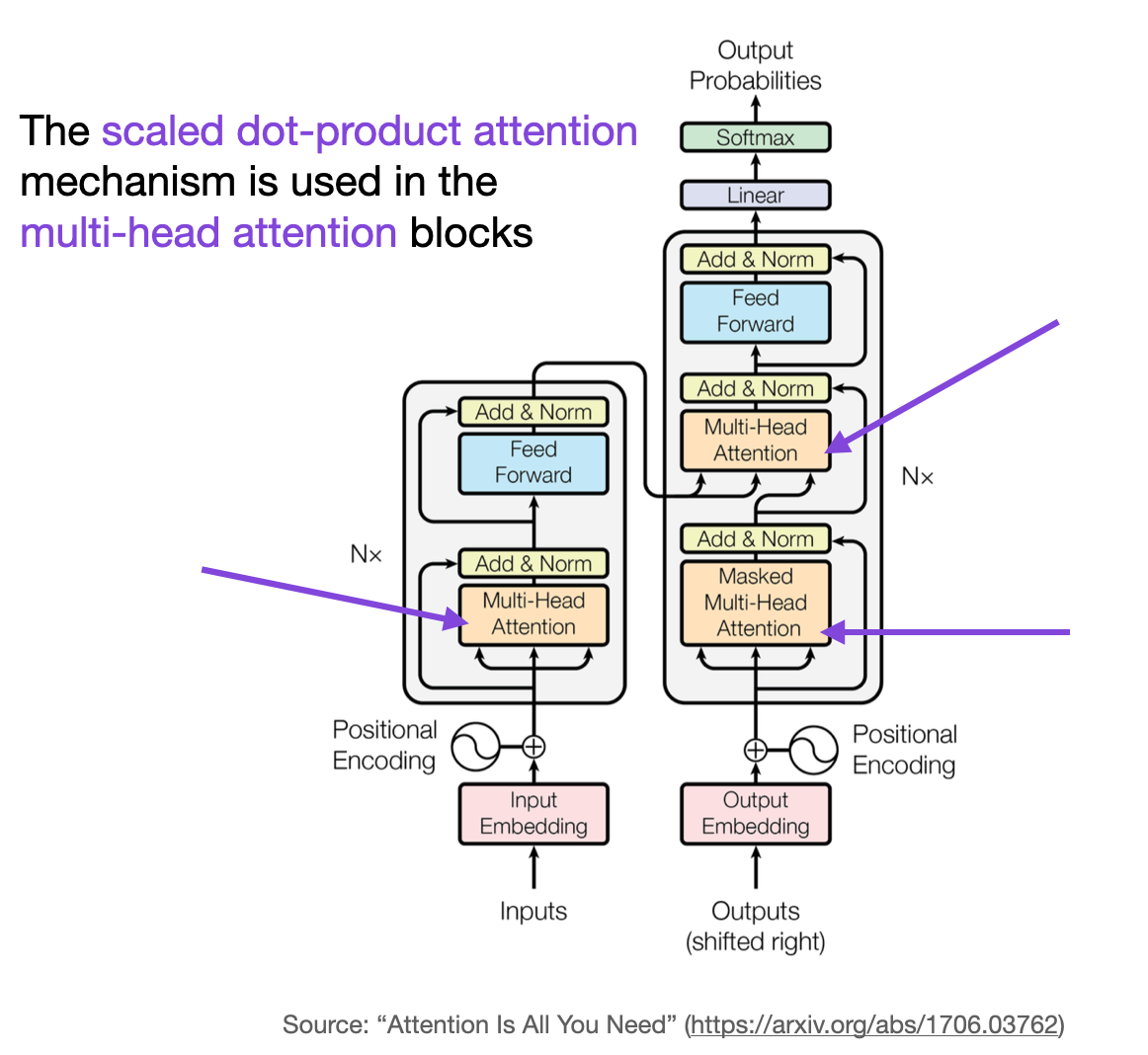
- What pre-training mechanisms are used for LLMs, explain a few
- Answer: Large Language Models utilize several pre-training mechanisms to learn from vast amounts of text data before being fine-tuned on specific tasks. Key mechanisms include: Masked Language Modeling (MLM): Popularized by BERT, this involves randomly masking some percentage of the input tokens and training the model to predict these masked tokens based on their context. This helps the model learn a deep understanding of language context and structure. Causal (Autoregressive) Language Modeling: Used by models like GPT, this approach trains the model to predict the next token in a sequence based on the tokens that precede it. This method is particularly effective for generative tasks where the model needs to produce coherent and contextually relevant text. Permutation Language Modeling: Introduced by XLNet, this technique involves training the model to predict a token within a sequence given the other tokens, where the order of the input tokens is permuted. This encourages the model to understand language in a more flexible and context-aware manner.
- Why is a multi-head attention needed?
- Answer: Answer: Multi-head attention allows a model to jointly attend to information from different representation subspaces at different positions. This is achieved by running several attention mechanisms (heads) in parallel, each with its own set of learnable weights. The key benefits include: Richer Representation: By capturing different aspects of the information (e.g., syntactic and semantic features) in parallel, multi-head attention allows the model to develop a more nuanced understanding of the input. Improved Attention Focus: Different heads can focus on different parts of the sequence, enabling the model to balance local and global information and improve its ability to capture complex dependencies. Increased Model Capacity: Without significantly increasing computational complexity, multi-head attention provides a way to increase the model's capacity, allowing it to learn more complex patterns and relationships in the data.
- What is RLHF, how is it used?
- Answer:
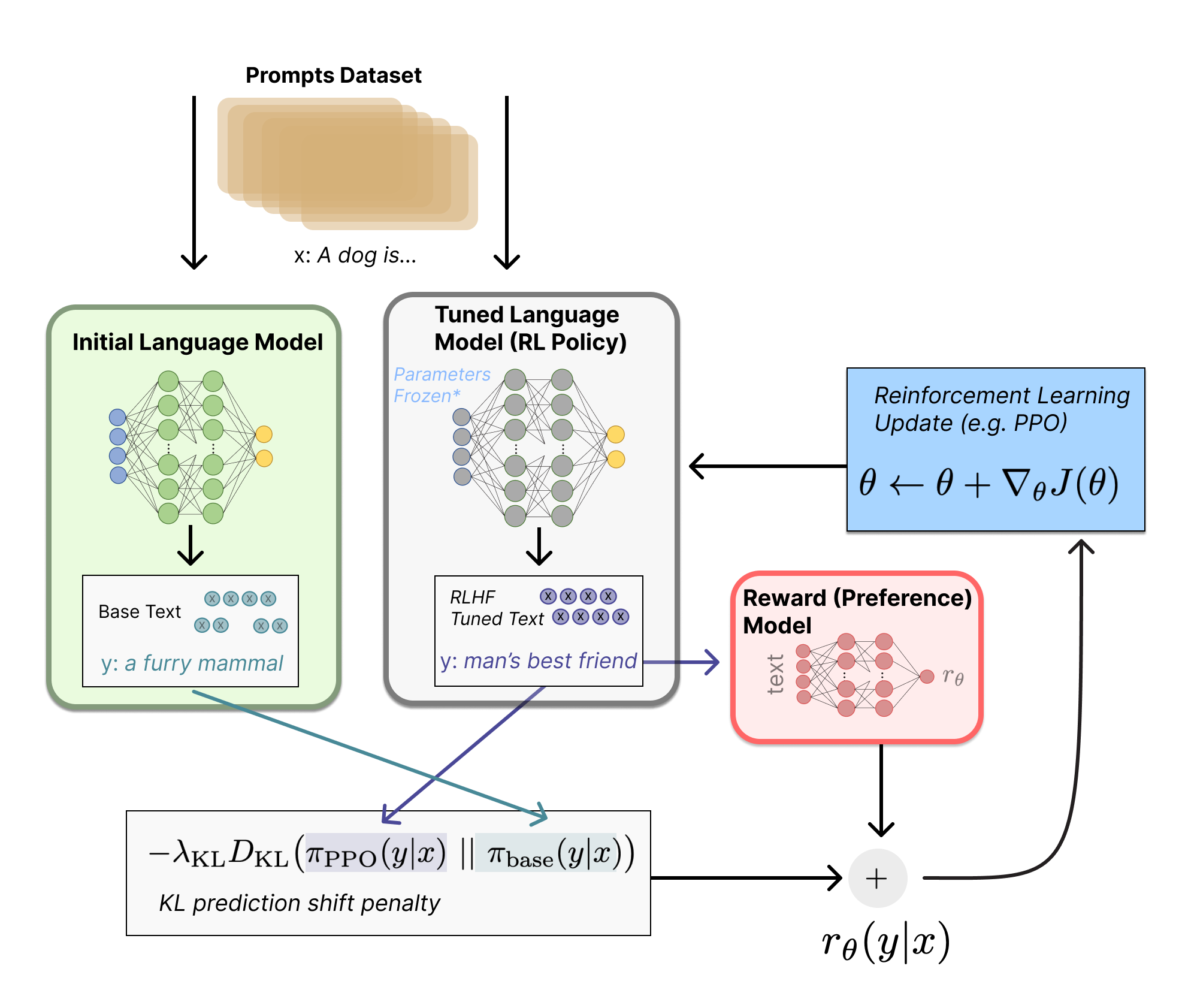 Image Source: https://huggingface.co/blog/rlhf
Reinforcement Learning from Human Feedback (RLHF) is a method used to fine-tune language models in a way that aligns their outputs with human preferences, values, and ethics. The process involves several steps:
Pre-training: The model is initially pre-trained on a large corpus of text data to learn a broad understanding of language.
Human Feedback Collection: Human annotators review the model's outputs in specific scenarios and provide feedback or corrections.
Reinforcement Learning: The model is fine-tuned using reinforcement learning techniques, where the human feedback serves as a reward signal, encouraging the model to produce outputs that are more aligned with human judgments.
RLHF is particularly useful for tasks requiring a high degree of alignment with human values, such as generating safe and unbiased content, enhancing the quality of conversational agents, or ensuring that AI-generated advice is ethically sound.
Read the article form Huggingface: https://huggingface.co/blog/rlhf
Image Source: https://huggingface.co/blog/rlhf
Reinforcement Learning from Human Feedback (RLHF) is a method used to fine-tune language models in a way that aligns their outputs with human preferences, values, and ethics. The process involves several steps:
Pre-training: The model is initially pre-trained on a large corpus of text data to learn a broad understanding of language.
Human Feedback Collection: Human annotators review the model's outputs in specific scenarios and provide feedback or corrections.
Reinforcement Learning: The model is fine-tuned using reinforcement learning techniques, where the human feedback serves as a reward signal, encouraging the model to produce outputs that are more aligned with human judgments.
RLHF is particularly useful for tasks requiring a high degree of alignment with human values, such as generating safe and unbiased content, enhancing the quality of conversational agents, or ensuring that AI-generated advice is ethically sound.
Read the article form Huggingface: https://huggingface.co/blog/rlhf
- What is catastrophic forgetting in the context of LLMs
- Answer: Catastrophic forgetting refers to the phenomenon where a neural network, including Large Language Models, forgets previously learned information upon learning new information. This occurs because neural networks adjust their weights during training to minimize the loss on the new data, which can inadvertently cause them to "forget" what they had learned from earlier data. This issue is particularly challenging in scenarios where models need to continuously learn from new data streams without losing their performance on older tasks.
- In a transformer-based sequence-to-sequence model, what are the primary functions of the encoder and decoder? How does information flow between them during both training and inference?
- Answer: In a transformer-based sequence-to-sequence model, the encoder and decoder serve distinct but complementary roles in processing and generating sequences: Encoder: The encoder processes the input sequence, capturing its informational content and contextual relationships. It transforms the input into a set of continuous representations, which encapsulate the input sequence's information in a form that the decoder can utilize. Decoder: The decoder receives the encoder's output representations and generates the output sequence, one element at a time. It uses the encoder's representations along with the previously generated elements to produce the next element in the sequence. During training and inference, information flows between the encoder and decoder primarily through the encoder's output representations. In addition, the decoder uses self-attention to consider its previous outputs when generating the next output, ensuring coherence and contextuality in the generated sequence. In some transformer variants, cross-attention mechanisms in the decoder also allow direct attention to the encoder's outputs at each decoding step, further enhancing the model's ability to generate relevant and accurate sequences based on the input.
- Why is positional encoding crucial in transformer models, and what issue does it address in the context of self-attention operations?
- Answer: Positional encoding is a fundamental aspect of transformer models, designed to imbue them with the ability to recognize the order of elements in a sequence. This capability is crucial because the self-attention mechanism at the heart of transformer models treats each element of the input sequence independently, without any inherent understanding of the position or order of elements. Without positional encoding, transformers would not be able to distinguish between sequences of the same set of elements arranged in different orders, leading to a significant loss in the ability to understand and generate meaningful language or process sequence data effectively. Addressing the Issue of Sequence Order in Self-Attention Operations: The self-attention mechanism allows each element in the input sequence to attend to all elements simultaneously, calculating the attention scores based on the similarity of their features. While this enables the model to capture complex relationships within the data, it inherently lacks the ability to understand how the position of an element in the sequence affects its meaning or role. For example, in language, the meaning of a sentence can drastically change with the order of words ("The cat ate the fish" vs. "The fish ate the cat"), and in time-series data, the position of data points in time is critical to interpreting patterns and trends. How Positional Encoding Works: To overcome this limitation, positional encodings are added to the input embeddings at the beginning of the transformer model. These encodings provide a unique signature for each position in the sequence, which is combined with the element embeddings, thus allowing the model to retain and utilize positional information throughout the self-attention and subsequent layers. Positional encodings can be designed in various ways, but they typically involve patterns that the model can learn to associate with sequence order, such as sinusoidal functions of different frequencies.
- When applying transfer learning to fine-tune a pre-trained transformer for a specific NLP task, what strategies can be employed to ensure effective knowledge transfer, especially when dealing with domain-specific data?
- Answer: Applying transfer learning to fine-tune a pre-trained transformer model involves several strategies to ensure that the vast knowledge the model has acquired is effectively transferred to the specific requirements of a new, potentially domain-specific task: Domain-Specific Pre-training: Before fine-tuning on the task-specific dataset, pre-train the model further on a large corpus of domain-specific data. This step helps the model to adapt its general language understanding capabilities to the nuances, vocabulary, and stylistic features unique to the domain in question. Gradual Unfreezing: Start fine-tuning by only updating the weights of the last few layers of the model and gradually unfreeze more layers as training progresses. This approach helps in preventing the catastrophic forgetting of pre-trained knowledge while allowing the model to adapt to the specifics of the new task. Learning Rate Scheduling: Employ differential learning rates across the layers of the model during fine-tuning. Use smaller learning rates for earlier layers, which contain more general knowledge, and higher rates for later layers, which are more task-specific. This strategy balances retaining what the model has learned with adapting to new data. Task-Specific Architectural Adjustments: Depending on the task, modify the model architecture by adding task-specific layers or heads. For instance, adding a classification head for a sentiment analysis task or a sequence generation head for a translation task allows the model to better align its outputs with the requirements of the task. Data Augmentation: Increase the diversity of the task-specific training data through techniques such as back-translation, synonym replacement, or sentence paraphrasing. This can help the model generalize better across the domain-specific nuances. Regularization Techniques: Implement techniques like dropout, label smoothing, or weight decay during fine-tuning to prevent overfitting to the smaller, task-specific dataset, ensuring the model retains its generalizability.
- Discuss the role of cross-attention in transformer-based encoder-decoder models. How does it facilitate the generation of output sequences based on information from the input sequence?
- Answer: Cross-attention is a mechanism in transformer-based encoder-decoder models that allows the decoder to focus on different parts of the input sequence as it generates each token of the output sequence. It plays a crucial role in tasks such as machine translation, summarization, and question answering, where the output depends directly on the input content. During the decoding phase, for each output token being generated, the cross-attention mechanism queries the encoder's output representations with the current state of the decoder. This process enables the decoder to "attend" to the most relevant parts of the input sequence, extracting the necessary information to generate the next token in the output sequence. Cross-attention thus facilitates a dynamic, content-aware generation process where the focus shifts across different input elements based on their relevance to the current decoding step. This ability to selectively draw information from the input sequence ensures that the generated output is contextually aligned with the input, enhancing the coherence, accuracy, and relevance of the generated text.
- ****Compare and contrast the impact of using sparse (e.g., cross-entropy) and dense (e.g., mean squared error) loss functions in training language models.
- Answer: Sparse and dense loss functions serve different roles in the training of language models, impacting the learning process and outcomes in distinct ways: Sparse Loss Functions (e.g., Cross-Entropy): These are typically used in classification tasks, including language modeling, where the goal is to predict the next word from a large vocabulary. Cross-entropy measures the difference between the predicted probability distribution over the vocabulary and the actual distribution (where the actual word has a probability of 1, and all others are 0). It is effective for language models because it directly penalizes the model for assigning low probabilities to the correct words and encourages sparsity in the output distribution, reflecting the reality that only a few words are likely at any given point. Dense Loss Functions (e.g., Mean Squared Error (MSE)): MSE measures the average of the squares of the differences between predicted and actual values. While not commonly used for categorical outcomes like word predictions in language models, it is more suited to regression tasks. In the context of embedding-based models or continuous output tasks within NLP, dense loss functions could be applied to measure how closely the generated embeddings match expected embeddings. Impact on Training and Model Performance: Focus on Probability Distribution: Sparse loss functions like cross-entropy align well with the probabilistic nature of language, focusing on improving the accuracy of probability distribution predictions for the next word. They are particularly effective for discrete output spaces, such as word vocabularies in language models. Sensitivity to Output Distribution: Dense loss functions, when applied in relevant NLP tasks, would focus more on minimizing the average error across all outputs, which can be beneficial for tasks involving continuous data or embeddings. However, they might not be as effective for typical language generation tasks due to the categorical nature of text.
- How can reinforcement learning be integrated into the training of large language models, and what challenges might arise in selecting suitable loss functions for RL-based approaches?
- Answer: Integrating reinforcement learning (RL) into the training of large language models involves using reward signals to guide the model's generation process towards desired outcomes. This approach, often referred to as Reinforcement Learning from Human Feedback (RLHF), can be particularly effective for tasks where traditional supervised learning methods fall short, such as ensuring the generation of ethical, unbiased, or stylistically specific text. Integration Process: Reward Modeling: First, a reward model is trained to predict the quality of model outputs based on criteria relevant to the task (e.g., coherence, relevance, ethics). This model is typically trained on examples rated by human annotators. Policy Optimization: The language model (acting as the policy in RL terminology) is then fine-tuned using gradients estimated from the reward model, encouraging the generation of outputs that maximize the predicted rewards. Challenges in Selecting Suitable Loss Functions: Defining Reward Functions: One of the primary challenges is designing or selecting a reward function that accurately captures the desired outcomes of the generation task. The reward function must be comprehensive enough to guide the model towards generating high-quality, task-aligned content without unintended biases or undesirable behaviors. Variance and Stability: RL-based approaches can introduce high variance and instability into the training process, partly due to the challenge of estimating accurate gradients based on sparse or delayed rewards. Selecting or designing loss functions that can mitigate these issues is crucial for successful integration. Reward Shaping and Alignment: Ensuring that the reward signals align with long-term goals rather than encouraging short-term, superficial optimization is another challenge. This requires careful consideration of how rewards are structured and potentially the use of techniques like reward shaping or constrained optimization. Integrating RL into the training of large language models holds the promise of more nuanced and goal-aligned text generation capabilities. However, it requires careful design and implementation of reward functions and loss calculations to overcome the inherent challenges of applying RL in complex, high-dimensional spaces like natural language.
Multimodal Models (Includes non-generative models)
1. In multimodal language models, how is information from visual and textual modalities effectively integrated to perform tasks such as image captioning or visual question answering?
- Answer: Multimodal language models integrate visual and textual information through sophisticated architectures that allow for the processing and analysis of data from both modalities. These models typically utilize a combination of convolutional neural networks (CNNs) for image processing and transformers or recurrent neural networks (RNNs) for text processing. The integration of information occurs in several ways: Joint Embedding Space: Both visual and textual inputs are mapped to a common embedding space where their representations can be compared directly. This allows the model to understand and manipulate both types of information in a unified manner. Attention Mechanisms: Attention mechanisms, particularly cross-modal attention, enable the model to focus on specific parts of an image given a textual query (or vice versa), facilitating detailed analysis and understanding of the relationships between visual and textual elements. Fusion Layers: After initial processing, the features from both modalities are combined using fusion layers, which might involve concatenation, element-wise addition, or more complex interactions. This fusion allows the model to leverage combined information for tasks like image captioning, where the model generates descriptive text for an image, or visual question answering, where the model answers questions based on the content of an image.
2. Explain the role of cross-modal attention mechanisms in models like VisualBERT or CLIP. How do these mechanisms enable the model to capture relationships between visual and textual elements?
- Answer:
Cross-modal attention mechanisms are pivotal in models like VisualBERT and CLIP, enabling these systems to dynamically focus on relevant parts of visual data in response to textual cues and vice versa. This mechanism works by allowing one modality (e.g., text) to guide the attention process in the other modality (e.g., image), thereby highlighting the features or areas that are most relevant to the task at hand.
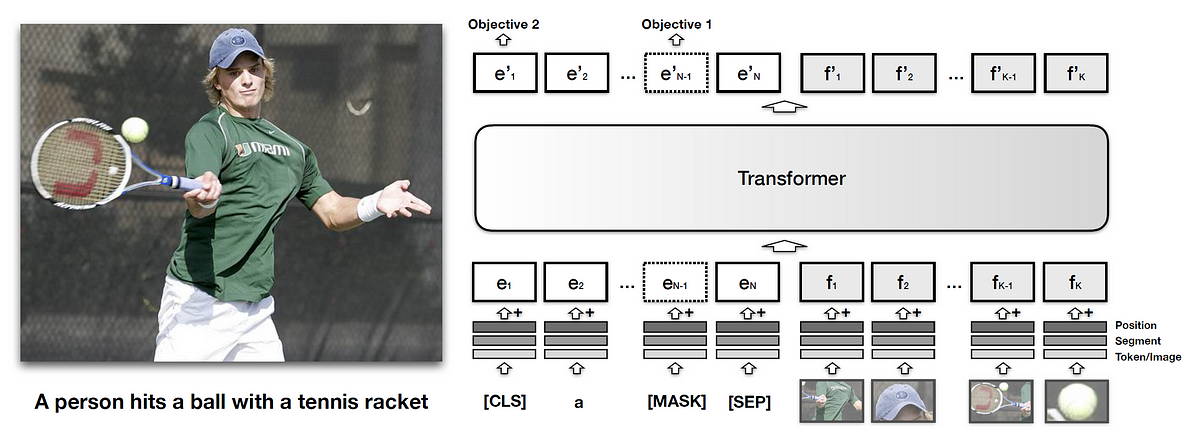 VisualBERT: Uses cross-modal attention within the transformer architecture to attend to specific regions of an image based on the context of the text. This is crucial for tasks where understanding the visual context is essential for interpreting the textual content correctly.
VisualBERT: Uses cross-modal attention within the transformer architecture to attend to specific regions of an image based on the context of the text. This is crucial for tasks where understanding the visual context is essential for interpreting the textual content correctly.
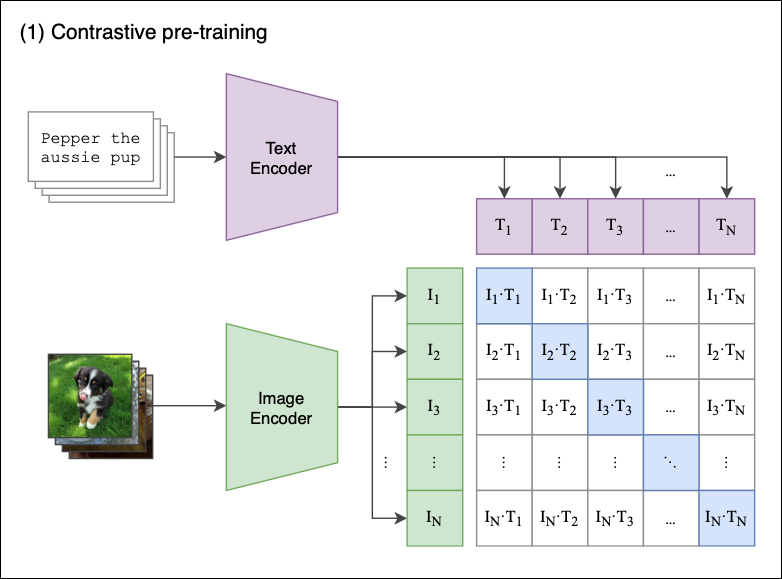 CLIP: Though not using cross-modal attention in the same way as VisualBERT, CLIP learns to associate images and texts effectively by training on a vast dataset of image-text pairs. It uses contrastive learning to maximize the similarity between corresponding text and image embeddings while minimizing the similarity between non-corresponding pairs.
In both cases, the cross-modal attention or learning mechanisms allow the models to understand and leverage the complex relationships between visual elements and textual descriptions, improving their performance on tasks that require a nuanced understanding of both modalities.
CLIP: Though not using cross-modal attention in the same way as VisualBERT, CLIP learns to associate images and texts effectively by training on a vast dataset of image-text pairs. It uses contrastive learning to maximize the similarity between corresponding text and image embeddings while minimizing the similarity between non-corresponding pairs.
In both cases, the cross-modal attention or learning mechanisms allow the models to understand and leverage the complex relationships between visual elements and textual descriptions, improving their performance on tasks that require a nuanced understanding of both modalities.
3. For tasks like image-text matching, how is the training data typically annotated to create aligned pairs of visual and textual information, and what considerations should be taken into account?
- Answer: For image-text matching tasks, the training data consists of pairs of images and textual descriptions that are closely aligned in terms of content and context. Annotating such data typically involves: Manual Annotation: Human annotators describe images or annotate existing descriptions to ensure they accurately reflect the visual content. This process requires careful guideline development to maintain consistency and accuracy in the descriptions. Automated Techniques: Some datasets are compiled using automated techniques, such as scraping image-caption pairs from the web. However, these methods require subsequent cleaning and verification to ensure high data quality. Considerations: When annotating data, it's important to consider diversity (in terms of both imagery and language), bias (to avoid reinforcing stereotypes or excluding groups), and specificity (descriptions should be detailed and closely aligned with the visual content). Additionally, the scalability of the annotation process is a practical concern, especially for large datasets.
4. When training a generative model for image synthesis, what are common loss functions used to evaluate the difference between generated and target images, and how do they contribute to the training process?
- Answer: In image synthesis, common loss functions include: Pixel-wise Loss Functions: Such as Mean Squared Error (MSE) or Mean Absolute Error (MAE), which measure the difference between corresponding pixels in the generated and target images. These loss functions are straightforward and contribute to ensuring overall fidelity but may not capture perceptual similarities well. Adversarial Loss: Used in Generative Adversarial Networks (GANs), where a discriminator model is trained to distinguish between real and generated images, providing a signal to the generator on how to improve. This loss function encourages the generation of images that are indistinguishable from real images, contributing to the realism of synthesized images. Perceptual Loss: Measures the difference in high-level features extracted from pre-trained deep neural networks. This loss function is designed to capture perceptual and semantic similarities between images, contributing to the generation of visually and contextually coherent images.
5. What is perceptual loss, and how is it utilized in image generation tasks to measure the perceptual similarity between generated and target images? How does it differ from traditional pixel-wise loss functions?
- Answer: Perceptual loss measures the difference in high-level features between the generated and target images, as extracted by a pre-trained deep neural network (usually a CNN trained on a large image classification task). This approach focuses on perceptual and semantic similarities rather than pixel-level accuracy. Utilization in Image Generation: Perceptual loss is used to guide the training of generative models by encouraging them to produce images that are similar to the target images in terms of content and style, rather than exactly matching pixel values. This is particularly useful for tasks like style transfer, super-resolution, and photorealistic image synthesis, where the goal is to generate images that look visually pleasing and coherent to human observers. Difference from Pixel-wise Loss Functions: Unlike pixel-wise loss functions (e.g., MSE or MAE) that measure the direct difference between corresponding pixels, perceptual loss operates at a higher level of abstraction, capturing differences in textures, shapes, and patterns that contribute to the overall perception of the image. This makes it more aligned with human visual perception, leading to more aesthetically pleasing and contextually appropriate image synthesis.
- What is Masked language-image modeling?
- Answer: Masked language-image modeling is a training technique used in multimodal models to learn joint representations of textual and visual information. Similar to the masked language modeling approach used in BERT for text, this method involves randomly masking out parts of the input (both in the image and the text) and training the model to predict the masked elements based on the context provided by the unmasked elements. In Images: This might involve masking portions of the image and asking the model to predict the missing content based on the surrounding visual context and any associated text. In Text: Similarly, words or phrases in the text may be masked, and the model must use the visual context along with the remaining text to predict the missing words. This approach encourages the model to develop a deep, integrated understanding of the content and context across both modalities, enhancing its capabilities in tasks that require nuanced understanding and manipulation of visual and textual information.
- How do attention weights obtained from the cross-attention mechanism influence the generation process in multimodal models? What role do these weights play in determining the importance of different modalities?
- Answer: In multimodal models, attention weights obtained from the cross-attention mechanism play a crucial role in the generation process by dynamically determining how much importance to give to different parts of the input from different modalities. These weights influence the model's focus during the generation process in several ways: Highlighting Relevant Information: The attention weights enable the model to focus on the most relevant parts of the visual input when processing textual information and vice versa. For example, when generating a caption for an image, the model can focus on specific regions of the image that are most pertinent to the words being generated. Balancing Modalities: The weights help in balancing the influence of each modality on the generation process. Depending on the task and the context, the model might rely more heavily on textual information in some instances and on visual information in others. The attention mechanism dynamically adjusts this balance. Enhancing Contextual Understanding: By allowing the model to draw on context from both modalities, the attention weights contribute to a richer, more nuanced understanding of the input, leading to more accurate and contextually appropriate outputs. The ability of cross-attention mechanisms to modulate the influence of different modalities through attention weights is a powerful feature of multimodal models, enabling them to perform complex tasks that require an integrated understanding of visual and textual information.
- What are the unique challenges in training multimodal generative models compared to unimodal generative models?
- Answer: Training multimodal generative models introduces unique challenges not typically encountered in unimodal generative models: Data Alignment: One of the primary challenges is ensuring proper alignment between different modalities. For instance, matching specific parts of an image with corresponding textual descriptions requires sophisticated modeling techniques to accurately capture and reflect these relationships. Complexity and Scalability: Multimodal generative models deal with data of different types (e.g., text, images, audio), each requiring different processing pipelines. Managing this complexity while scaling the model to handle large datasets effectively is a significant challenge. Cross-Modal Coherence: Generating coherent output that makes sense across all modalities (e.g., an image that accurately reflects a given text description) is challenging. The model must understand and maintain the context and semantics across modalities. Diverse Data Representation: Different modalities have inherently different data representations (e.g., pixels for images, tokens for text). Designing a model architecture that can handle these diverse representations and still learn meaningful cross-modal interactions is challenging. Sparse Data: In many cases, comprehensive datasets that cover the vast spectrum of possible combinations of modalities are not available, leading to sparse data issues. This can make it difficult for the model to learn certain cross-modal relationships.
- How do multimodal generative models address the issue of data sparsity in training?
- Answer: Current multimodal generative models employ several strategies to mitigate the issue of data sparsity during training: Data Augmentation: By artificially augmenting the dataset (e.g., generating new image-text pairs through transformations or translations), models can be exposed to a broader range of examples, helping to fill gaps in the training data. Transfer Learning: Leveraging pre-trained models on large unimodal datasets can provide a strong foundational knowledge that the multimodal model can build upon. This approach helps the model to generalize better across sparse multimodal datasets. Few-Shot and Zero-Shot Learning: These techniques are particularly useful for handling data sparsity by enabling models to generalize to new, unseen examples with minimal or no additional training data. Synthetic Data Generation: Generating synthetic examples of underrepresented modalities or combinations can help to balance the dataset and provide more comprehensive coverage of the possible input space. Regularization Techniques: Implementing regularization methods can prevent overfitting on the limited available data, helping the model to better generalize across sparse examples.
- Explain the concept of Vision-Language Pre-training (VLP) and its significance in developing robust vision-language models.
- Answer: Vision-Language Pre-training involves training models on large datasets containing both visual (images, videos) and textual data to learn general representations that can be fine-tuned for specific vision-language tasks. VLP is significant because it allows models to capture rich, cross-modal semantic relationships between visual and textual information, leading to improved performance on tasks like visual question answering, image captioning, and text-based image retrieval. By leveraging pre-trained VLP models, developers can achieve state-of-the-art results on various vision-language tasks with relatively smaller datasets during fine-tuning, enhancing the model's understanding and processing of multimodal information.
- How do models like CLIP and DALL-E demonstrate the integration of vision and language modalities?
- Answer: CLIP (Contrastive Language-Image Pre-training) and DALL-E (a model designed for generating images from textual descriptions) are two prominent examples of models that integrate vision and language modalities effectively: CLIP: CLIP learns visual concepts from natural language descriptions, training on a diverse range of images paired with textual descriptions. It uses a contrastive learning approach to align the image and text representations in a shared embedding space, enabling it to perform a wide range of vision tasks using natural language as input. CLIP demonstrates the power of learning from natural language supervision and its ability to generalize across different vision tasks without task-specific training data. DALL-E: DALL-E generates images from textual descriptions, demonstrating a deep understanding of both the content described in the text and how that content is visually represented. It uses a version of the GPT-3 architecture adapted for generating images, showcasing the integration of vision and language by creating coherent and often surprisingly accurate visual representations of described scenes, objects, and concepts. These models exemplify the potential of vision-language integration, highlighting how deep learning can bridge the gap between textual descriptions and visual representations to enable creative and flexible applications.
- How do attention mechanisms enhance the performance of vision-language models?
- Answer: Attention mechanisms significantly enhance the performance of vision-language models in multimodal learning by allowing models to dynamically focus on relevant parts of the input data: Cross-Modal Attention: These mechanisms enable the model to attend to specific regions of an image given textual input or vice versa. This selective attention helps the model to extract and integrate relevant information from both modalities, improving its ability to perform tasks such as image captioning or visual question answering by focusing on the salient details that are most pertinent to the task at hand. Self-Attention in Language: Within the language modality, self-attention allows the model to emphasize important words or phrases in a sentence, aiding in understanding textual context and semantics that are relevant to the visual data. Self-Attention in Vision: In the visual modality, self-attention mechanisms can highlight important areas or features within an image, helping to better align these features with textual descriptions or queries. By leveraging attention mechanisms, vision-language models can achieve a more nuanced and effective integration of information across modalities, leading to more accurate, context-aware, and coherent multimodal representations and outputs.
Embeddings
1. What is the fundamental concept of embeddings in machine learning, and how do they represent information in a more compact form compared to raw input data?
- Answer Embeddings are dense, low-dimensional representations of high-dimensional data, serving as a fundamental concept in machine learning to efficiently capture the essence of data entities (such as words, sentences, or images) in a form that computational models can process. Unlike raw input data, which might be sparse and high-dimensional (e.g., one-hot encoded vectors for words), embeddings map these entities to continuous vectors, preserving semantic relationships while significantly reducing dimensionality. This compact representation enables models to perform operations and learn patterns more effectively, capturing similarities and differences in the underlying data. For instance, in natural language processing, word embeddings place semantically similar words closer in the embedding space, facilitating a more nuanced understanding of language by machine learning models.
- Compare and contrast word embeddings and sentence embeddings. How do their applications differ, and what considerations come into play when choosing between them?
- Answer:
Word Embeddings:
- Scope: Represent individual words as vectors, capturing semantic meanings based on usage context.
- Applications: Suited for word-level tasks like synonym detection, part-of-speech tagging, and named entity recognition.
- Characteristics: Offer static representations where each word has one embedding, potentially limiting their effectiveness for words with multiple meanings.
- Scope: Extend the embedding concept to entire sentences or longer texts, aiming to encapsulate the overall semantic content.
- Applications: Used for tasks requiring comprehension of broader contexts, such as document classification, semantic text similarity, and sentiment analysis.
- Characteristics: Provide dynamic representations that consider word interactions and sentence structure, better capturing the context and nuances of language use.
Considerations for Choosing Between Them:
- Task Requirements: Word embeddings are preferred for analyzing linguistic features at the word level, while sentence embeddings are better for tasks involving understanding of sentences or larger text units.
- Contextual Sensitivity: Sentence embeddings or contextual word embeddings (like BERT) are more adept at handling the varying meanings of words across different contexts.
- Computational Resources: Generating and processing sentence embeddings, especially from models like BERT, can be more resource-intensive.
- Data Availability: The effectiveness of embeddings correlates with the diversity and size of the training data.
- Explain the concept of contextual embeddings. How do models like BERT generate contextual embeddings, and in what scenarios are they advantageous compared to traditional word embeddings?
- Answer: Contextual embeddings are dynamic representations of words that change based on the word's context within a sentence, offering a more nuanced understanding of language. Models like BERT generate contextual embeddings by using a deep transformer architecture, processing the entire sentence at once, allowing the model to capture the relationships and dependencies between words. Advantages: Contextual embeddings excel over traditional, static word embeddings in tasks requiring a deep understanding of context, such as sentiment analysis, where the meaning of a word can shift dramatically based on surrounding words, or in language ambiguity resolution tasks like homonym and polysemy disambiguation. They provide a richer semantic representation by considering the word's role and relations within a sentence.
- Discuss the challenges and strategies involved in generating cross-modal embeddings, where information from multiple modalities, such as text and image, is represented in a shared embedding space.
- Answer: Generating cross-modal embeddings faces several challenges, including aligning semantic concepts across modalities with inherently different data characteristics and ensuring the embeddings capture the essence of both modalities. Strategies to address these challenges include: Joint Learning: Training models on tasks that require understanding both modalities simultaneously, encouraging the model to find a common semantic ground. Canonical Correlation Analysis (CCA): A statistical method to align the embeddings from different modalities in a shared space by maximizing their correlation. Contrastive Learning: A technique that brings embeddings of similar items closer together while pushing dissimilar items apart, applied across modalities to ensure semantic alignment.
5. When training word embeddings, how can models be designed to effectively capture representations for rare words with limited occurrences in the training data?
- Answer: To capture representations for rare words, models can: Subword Tokenization: Break down rare words into smaller units (like morphemes or syllables) for which embeddings can be learned more robustly. Smoothing Techniques: Use smoothing or regularization techniques to borrow strength from similar or more frequent words. Contextual Augmentation: Increase the representation of rare words by artificially augmenting sentences containing them in the training data.
- Discuss common regularization techniques used during the training of embeddings to prevent overfitting and enhance the generalization ability of models.
- Answer: Common regularization techniques include: L2 Regularization: Adds a penalty on the magnitude of embedding vectors, encouraging them to stay small and preventing overfitting to specific training examples. Dropout: Randomly zeroes elements of the embedding vectors during training, forcing the model to rely on a broader context rather than specific embeddings. Noise Injection: Adds random noise to embeddings during training, enhancing robustness and generalization by preventing reliance on precise values.
7. How can pre-trained embeddings be leveraged for transfer learning in downstream tasks, and what advantages does transfer learning offer in terms of embedding generation?
- Answer:
Pre-trained embeddings, whether for words, sentences, or even larger textual units, are a powerful resource in the machine learning toolkit, especially for tasks in natural language processing (NLP). These embeddings are typically generated from large corpora of text using models trained on a wide range of language understanding tasks. When leveraged for transfer learning, pre-trained embeddings can significantly enhance the performance of models on downstream tasks, even with limited labeled data.
Leveraging Pre-trained Embeddings for Transfer Learning:
- Initialization: In this approach, pre-trained embeddings are used to initialize the embedding layer of a model before training on a specific downstream task. This gives the model a head start by providing it with rich representations of words or sentences, encapsulating a broad understanding of language.
- Feature Extraction: Here, pre-trained embeddings are used as fixed features for downstream tasks. The embeddings serve as input to further layers of the model that are trained to accomplish specific tasks, such as classification or entity recognition. This approach is particularly useful when the downstream task has relatively little training data.
- What is quantization in the context of embeddings, and how does it contribute to reducing the memory footprint of models while preserving representation quality?
- Answer: Quantization involves converting continuous embedding vectors into a discrete, compact format, typically by reducing the precision of the numbers used to represent each component of the vectors. This process significantly reduces the memory footprint of the embeddings and the overall model by allowing the storage and computation of embeddings in lower-precision formats without substantially compromising their quality. Typically, embeddings are stored as 32-bit floating-point numbers. Quantization involves converting these high-precision embeddings into lower-precision formats, such as 16-bit floats (float16) or even 8-bit integers (int8), thereby reducing the model's memory footprint. Quantization is particularly beneficial for deploying large-scale models on resource-constrained environments, such as mobile devices or in browser applications, enabling faster loading times and lower memory usage.
- When dealing with high-cardinality categorical features in tabular data, how would you efficiently implement and train embeddings using a neural network to capture meaningful representations?
- Answer: For high-cardinality categorical features, embeddings can be efficiently implemented and trained by: Embedding Layers: Introducing embedding layers in the neural network specifically designed to convert high-cardinality categorical features into dense, low-dimensional embeddings. Batch Training: Utilizing mini-batch training to efficiently handle large datasets and high-cardinality features by processing a subset of data at a time. Regularization: Applying regularization techniques to prevent overfitting, especially important for categories with few occurrences.
- When dealing with large-scale embeddings, propose and implement an efficient method for nearest neighbor search to quickly retrieve similar embeddings from a massive database.
- Answer For efficient nearest neighbor search in large-scale embeddings, methods such as approximate nearest neighbor (ANN) algorithms can be used. Techniques like locality-sensitive hashing (LSH), tree-based partitioning (e.g., KD-trees, Ball trees), or graph-based approaches (e.g., HNSW) enable fast retrieval by approximating the nearest neighbors without exhaustively comparing every pair of embeddings. Implementing these methods involves constructing an index from the embeddings that can quickly narrow down the search space for potential neighbors.
- In scenarios where an LLM encounters out-of-vocabulary words during embedding generation, propose strategies for handling such cases.
- Answer: To handle out-of-vocabulary (OOV) words, strategies include: Subword Tokenization: Breaking down OOV words into known subwords or characters and aggregating their embeddings. Zero or Random Initialization: Assigning a zero or randomly generated vector for OOV words, optionally fine-tuning these embeddings if training data is available. Fallback to Similar Words: Using embeddings of semantically or morphologically similar words as a proxy for OOV words.
- Propose metrics for quantitatively evaluating the quality of embeddings generated by an LLM. How can the effectiveness of embeddings be assessed in tasks like semantic similarity or information retrieval?
- Answer: Quality of embeddings can be evaluated using metrics such as: Cosine Similarity: Measures the cosine of the angle between two embedding vectors, useful for assessing semantic similarity. Precision@k and Recall@k for Information Retrieval: Evaluates how many of the top-k retrieved documents (or embeddings) are relevant to a query. Word Embedding Association Test (WEAT): Assesses biases in embeddings by measuring associations between sets of target words and attribute words.
- Explain the concept of triplet loss in the context of embedding learning.
- Answer Triplet loss is used to learn embeddings by ensuring that an anchor embedding is closer to a positive embedding (similar content) than to a negative embedding (dissimilar content) by a margin. This loss function helps in organizing the embedding space such that embeddings of similar instances cluster together, while embeddings of dissimilar instances are pushed apart, enhancing the model's ability to discriminate between different categories or concepts.
14. In loss functions like triplet loss or contrastive loss, what is the significance of the margin parameter?
- Answer: The margin parameter in triplet or contrastive loss functions specifies the desired minimum difference between the distances of positive and negative pairs to the anchor. Adjusting the margin impacts the strictness of the separation enforced in the embedding space, influencing both the learning process and the quality of the resulting embeddings. A larger margin encourages embeddings to be spread further apart, potentially improving the model's discrimination capabilities, but if set too high, it might lead to training difficulties or degraded performance due to an overly stringent separation criterion.
Training, Inference and Evaluation
- Discuss challenges related to overfitting in LLMs during training. What strategies and regularization techniques are effective in preventing overfitting, especially when dealing with massive language corpora?
- Answer: Challenges: Overfitting in Large Language Models can lead to models that perform well on training data but poorly on unseen data. This is particularly challenging with massive language corpora, where the model may memorize rather than generalize. Strategies and Techniques: Data Augmentation: Increases the diversity of the training set, helping models to generalize better. Regularization: Techniques such as dropout, L2 regularization, and early stopping can discourage the model from memorizing the training data. Model Simplification: Although challenging for LLMs, reducing model complexity can mitigate overfitting. Batch Normalization: Helps in stabilizing the learning process and can contribute to preventing overfitting.
2. Large Language Models often require careful tuning of learning rates. How do you adapt learning rates during training to ensure stable convergence and efficient learning for LLMs?
- Answer: Adapting Learning Rates: Learning Rate Scheduling: Gradually reducing the learning rate during training can help in achieving stable convergence. Techniques like step decay, exponential decay, or cosine annealing are commonly used. Adaptive Learning Rate Algorithms: Methods such as Adam or RMSprop automatically adjust the learning rate based on the training process, improving efficiency and stability.
- When generating sequences with LLMs, how can you handle long context lengths efficiently? Discuss techniques for managing long inputs during real-time inference.
- Answer:
Some solutions are:
- Fine-tuning on Longer Contexts: Training a model on shorter sequences and then fine-tuning it on longer sequences may seem like a solution. However, this approach may not work well with the original Transformer due to Positional Sinusoidal Encoding limitations.
- Flash Attention: FlashAttention optimizes the attention mechanism for GPUs by breaking computations into smaller blocks, reducing memory transfer overheads and enhancing processing speed.
- Multi-Query Attention (MQA): MQA is an optimization over the standard Multi-Head Attention (MHA), sharing a common weight matrix for projecting "key" and "value" across heads, leading to memory efficiency and faster inference speed.
- Positional Interpolation (PI): Adjusts position indices to fit within the existing context size using mathematical interpolation techniques.
- Rotary Positional Encoding (RoPE): Rotates existing embeddings based on their positions, capturing sequence position in a more fluid manner.
- ALiBi (Attention with Linear Biases): Enhances the Transformer's adaptability to varied sequence lengths by introducing biases in the attention mechanism, optimizing performance on extended contexts.
- Sparse Attention: Considers only some tokens within the content size when calculating attention scores, making computation linear with respect to input token size.
4. What evaluation metrics can be used to judge LLM generation quality
- Answer:
Common metrics used to evaluate Language Model performance include:
- Perplexity: Measures how well the model predicts a sample of text. Lower perplexity values indicate better performance.
- Human Evaluation: Involves enlisting human evaluators to assess the quality of the model's output based on criteria like relevance, fluency, coherence, and overall quality.
- BLEU (Bilingual Evaluation Understudy): A metric primarily used in machine translation tasks. It compares the generated output with reference translations and measures their similarity.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Used for evaluating the quality of summaries. It compares generated summaries with reference summaries and calculates precision, recall, and F1-score.
- Diversity: Measures the variety and uniqueness of generated responses, often analyzed using metrics such as n-gram diversity or semantic similarity. Higher diversity scores indicate more diverse and unique outputs.
- Truthfulness Evaluation: Evaluating the truthfulness of LLMs involves techniques like comparing LLM-generated answers with human answers, benchmarking against datasets like TruthfulQA, and training true/false classifiers on LLM hidden layer activations.
- Hallucination in LLMs a known issue, how can you evaluate and mitigate it?
- Answer:
Some approaches to detect and mitigate hallucinations (source):
- Log Probability (Seq-Logprob):
- Introduced in the paper "Looking for a Needle in a Haystack" by Guerreiro et al. (2023).
- Utilizes length-normalized sequence log-probability to assess the confidence of the model's output.
- Effective for evaluating translation quality and detecting hallucinations, comparable to reference-based methods.
- Offers simplicity and ease of computation during the translation process.
- Sentence Similarity:
- Proposed in the paper "Detecting and Mitigating Hallucinations in Machine Translation" by David et al. (Dec 2022).
- Evaluates the percentage of source contribution to generated translations and identifies hallucinations by detecting low source contribution.
- Utilizes reference-based, internal measures, and reference-free techniques along with measures of semantic similarity between sentences.
- Techniques like LASER, LaBSE, and XNLI significantly improve detection and mitigation of hallucinations, outperforming previous approaches.
- SelfCheckGPT:
- Introduced in the paper "SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models" by Manakul et al. (2023).
- Evaluates hallucinations using GPT when output probabilities are unavailable, commonly seen in black-box scenarios.
- Utilizes variants such as SelfCheckGPT with BERTScore and SelfCheckGPT with Question Answering to assess informational consistency.
- Combination of different SelfCheckGPT variants provides complementary outcomes, enhancing the detection of hallucinations.
- GPT4 Prompting:
- Explored in the paper "Evaluating the Factual Consistency of Large Language Models Through News Summarization" by Tam et al. (2023).
- Focuses on summarization tasks and surveys different prompting techniques and models to detect hallucinations in summaries.
- Techniques include chain-of-thought prompting and sentence-by-sentence prompting, comparing various LLMs and baseline approaches.
- Few-shot prompts and combinations of prompts improve the performance of LLMs in detecting hallucinations.
- G-EVAL:
- Proposed in the paper "G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment" by Liu et al. (2023).
- Provides a framework for LLMs to evaluate the quality of Natural Language Generation (NLG) using chain of thoughts and form filling.
- Outperforms previous approaches by a significant margin, particularly effective for summarization and dialogue generation datasets.
- Combines prompts, chain-of-thoughts, and scoring functions to assess hallucinations and coherence in generated text.
- Log Probability (Seq-Logprob):
- What are mixture of experts models?
- Answer: Mixture of Experts (MoE) models consist of several specialized sub-models (experts) and a gating mechanism that decides which expert to use for a given input. This architecture allows for handling complex problems by dividing them into simpler, manageable tasks, each addressed by an expert in that area.
7. Why might over-reliance on perplexity as a metric be problematic in evaluating LLMs? What aspects of language understanding might it overlook?
- Answer Over-reliance on perplexity can be problematic because it primarily measures how well a model predicts the next word in a sequence, potentially overlooking aspects such as coherence, factual accuracy, and the ability to capture nuanced meanings or implications. It may not fully reflect the model's performance on tasks requiring deep understanding or creative language use.