Introduction to MM LLMs

1. Introduction to Multimodal LLMs
Most people were incredibly impressed when OpenAI's Sora made its debut in Feb 2024, seamlessly producing lifelike videos. Sora is a prime example of a multimodal LLM (MM-LLM), employing text to influence the generation of videos, a direction in research that has been evolving for several years. In the past year particularly, MM-LLMs have witnessed remarkable advancements, paving way for a new era of AI capable of processing and generating content across multiple modalities. These MM-LLMs represent a significant evolution of traditional LLMs, as they integrate information from various sources such as text, images, and audio to enhance their understanding and generation capabilities.
It's essential to note that not all multimodal systems are MLLMs. While some models combine text and image processing, true MLLMs encompass a broader range of modalities and integrate them seamlessly to enhance understanding and generation capabilities. In essence, MM-LLMs augment off-the-shelf LLMs with cost-effective training strategies, enabling them to support multimodal inputs or outputs. By leveraging the inherent reasoning and decision-making capabilities of LLMs, MM-LLMs empower a diverse range of multimodal tasks, spanning natural language understanding, computer vision, and audio processing.
Another notable example of an MLLM is OpenAI's GPT-4(Vision), which combines the language processing capabilities of the GPT series with image understanding capabilities. With GPT-4(Vision), the model can generate text-based descriptions of images, answer questions about visual content, and even generate captions for images. Similarly, Google's Gemini and Microsoft's KOSMOS-1 are pioneering MLLMs that demonstrate impressive capabilities in processing both text and images.
The applications of MLLMs are vast and diverse. MLLMs can analyze text inputs along with accompanying images or audio to derive deeper insights and context. For example, they can assist in sentiment analysis of social media posts by considering both the textual content and the accompanying images. In computer vision, MLLMs can enhance image recognition tasks by incorporating textual descriptions or audio cues, leading to more accurate and contextually relevant results. Additionally, in applications such as virtual assistants and chatbots, MLLMs can leverage multimodal inputs to provide more engaging and personalized interactions with users.
Beyond these examples, MLLMs have the potential to improve various industries and domains, including healthcare, education, entertainment, and autonomous systems. By seamlessly integrating information from different modalities, MLLMs can enable AI systems to better understand and interact with the world, ultimately leading to more intelligent and human-like behavior.
In the following sections of this beginner friendly guide, we will explore the core components, training paradigms, state-of-the-art advancements, evaluation methods, challenges, and future directions of MLLMs, shedding light on the exciting possibilities and implications of this groundbreaking technology.
2. Core Components
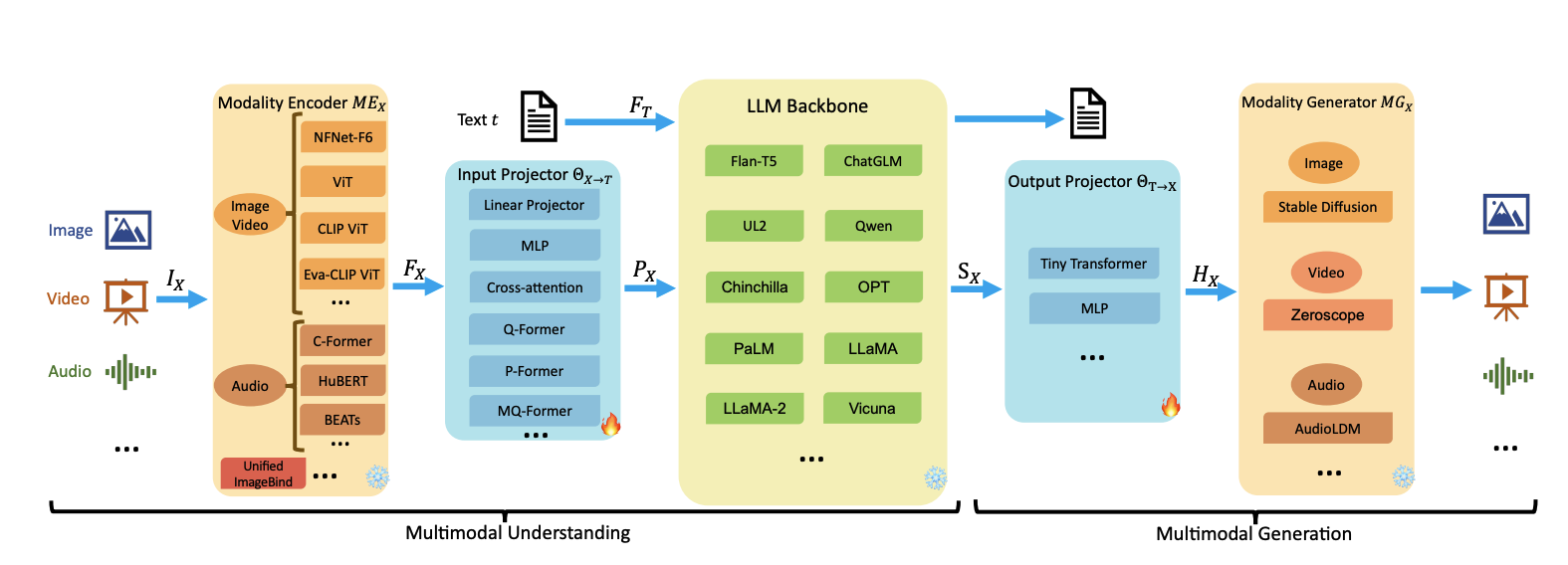
Image Source: https://arxiv.org/pdf/2401.13601
Most MM-LLMs can be categorized into key components, each differentiated by specific design choices. In this guide, we will adopt the component framework outlined in the paper "MM-LLMs: Recent Advances in Multimodal Large Language Models” (link). These components are designed to seamlessly integrate information from diverse modalities, such as text, images, videos, audio, etc. enabling the model to understand and generate content that spans multiple modalities.
2.1 Modality Encoder
The Modality Encoder (ME) plays a pivotal role in MM-LLMs by encoding inputs from various modalities into corresponding feature representations. Its function is akin to translating the information from different modalities into a common format that the model can process effectively. For example, ME processes images, videos, audio, and 3D data, converting them into feature vectors that capture their essential characteristics. This step is essential for facilitating the subsequent processing of multimodal inputs by the model. Examples of Modality Encoders for different modalities include ViT, OpenCLIP etc.
2.2 Input Projector
Once the inputs from different modalities are encoded into feature representations, the Input Projector comes into play. This component aligns the encoded features of other modalities with the textual feature space, enabling the model to effectively integrate information from multiple sources. By aligning the features from different modalities with the textual features, the Input Projector ensures that the model can generate coherent and contextually relevant outputs that incorporate information from all modalities present in the input. This can be implemented using Linear Projector, Multi-Layer Perceptron (MLP), Cross-attention, Q-Former etc.
2.3 LLM Backbone
At the core of MM-LLMs lies the Language Model Backbone, which processes the representations from various modalities, engages in semantic understanding, reasoning, and decision-making regarding the inputs. The LLM Backbone produces textual outputs and signal tokens from other modalities, acting as instructions to guide the generation process. By leveraging the capabilities of pre-trained LLMs, MM-LLMs inherit properties like zero-shot generalization and few-shot learning, enabling them to generate diverse and contextually relevant multimodal content. Examples of commonly used LLMs in MM-LLMs include Flan-T5, PaLM, LLaMA or any text-generation LLM.
2.4 Output Projector
The Output Projector serves as the bridge between the LLM Backbone and the Modality Generator, mapping the signal token representations from the LLM Backbone into features understandable to the Modality Generator. This component ensures that the generated multimodal content is aligned with the textual representations produced by the model. By minimizing the distance between the mapped features and the conditional text representations, the Output Projector facilitates the generation of coherent and semantically consistent multimodal outputs. This can be implemented using a Tiny Transformer with a learnable decoder feature sequence or MLP.
2.5 Modality Generator
Finally, the Modality Generator is responsible for producing outputs in distinct modalities based on the aligned textual representations. By leveraging off-the-shelf Latent Diffusion Models (LDMs), the Modality Generator synthesizes multimodal content that aligns with the input text and other modalities. During training, the Modality Generator utilizes ground truth content to learn to generate coherent and contextually relevant multimodal outputs.
2.1 Task Example:
Let's understand how all these components work together in an use-case for generating captions for multimedia content, given inputs from images and textual descriptions as shown in the image below:

Here's how each component would function:
- Modality Encoder:
- Given an input image, the Modality Encoder encodes the image features using a pre-trained visual encoder like ViT.
- Similarly, the textual description is encoded using the language encoder of the LLM.
- Input Projector:
- The Input Projector aligns the encoded image features with the text feature space.
- This alignment ensures that the image features are compatible with the textual features for further processing by the LLM Backbone.
- It might use methods like Cross-attention to effectively align features from different modalities.
- LLM Backbone:
- The LLM Backbone processes the aligned representations from various modalities.
- It performs semantic understanding and reasoning to generate captions for the given image and text.
- This component integrates information from both modalities to generate coherent and contextually relevant captions.
- Output Projector:
- The Output Projector maps the generated textual representations (captions) into features understandable to the Modality Generator.
- This mapping ensures that the generated captions are translated into features that can guide the Modality Generator to produce multimedia content.
- Modality Generator:
- The Modality Generator takes the mapped textual representations along with any additional signals from the LLM Backbone.
- Based on these inputs, the Modality Generator synthesizes multimedia content corresponding to the generated captions.
- The synthesized multimedia content is aligned with the textual descriptions and can include images, videos, or audio corresponding to the given input.
3. Data and Training Paradigms
Training MM-LLMs generally includes 2 steps, similar to that for LLMs:
3.1 Pretraining (MM-PT):
During the pretraining phase of a MM-LLM, the model encounters a vast dataset comprising pairs of various modalities, like images and text, audio and text, video and text, or other combinations, depending on the task at hand. The aim of pretraining is to initialize the model's parameters and facilitate the learning of representations that capture meaningful connections between different modalities and their respective textual descriptions.
Throughout pretraining, the MM-LLM acquires the ability to extract features from each modality and merge them to produce cohesive representations.
Typically, three primary types of data are utilized:
- Gold Pairs: This category involves precise matching data, where pairs of modalities are associated with corresponding text descriptions. For example, in the context of images, this would include images paired with their text captions.
- Interleaved Pairs: The second type comprises interleaved documents containing modalities and text. Unlike precise matching data, which usually includes concise and highly pertinent text closely linked to the associated modalities, interleaved data tends to encompass lengthier and more varied text with lower average relevance to the accompanying modalities. This aids in enhancing the system's generalization and robustness. In the case of images, this would resemble captioning data, but the text would possess less relevance to the surrounding images.
- Text Only: Additionally, text-only data is incorporated into the training process to uphold and bolster the language comprehension capabilities of the underlying pretrained language model.
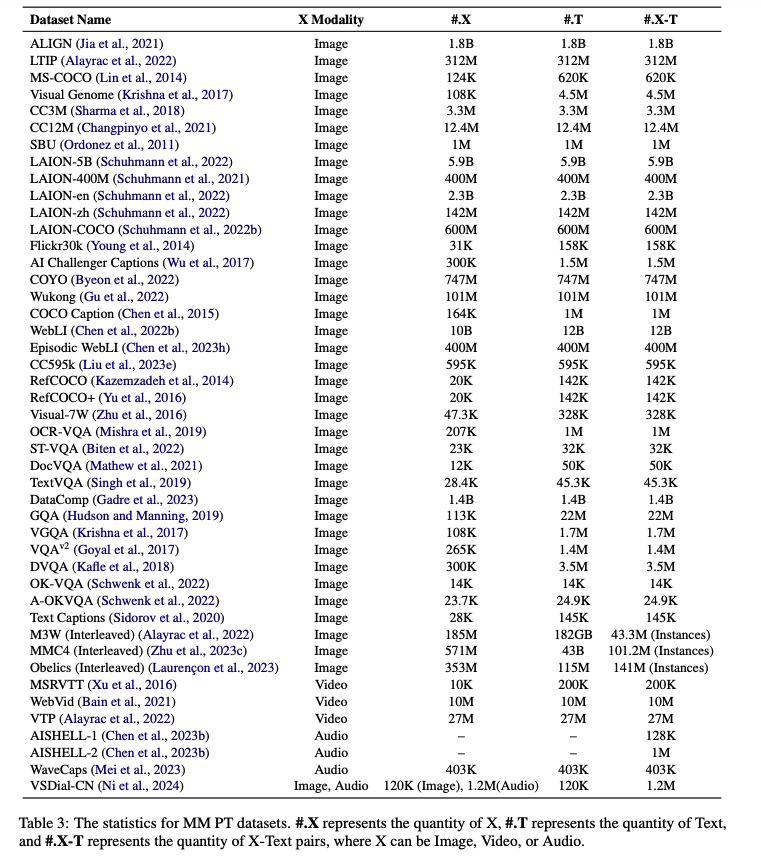
The below table from this paper provides a list of popular training datasets and their sizes:
3.2 Instruction Tuning (MM-IT):
In the instruction tuning phase for MM-LLMs, the model is fine-tuned to perform specific task. Let us take the example of a task like Visual Question Answering (VQA).
By providing explicit instructions alongside the input data. Let's break down how this works using a VQA example:
- Task Formulation: Initially, the task is formulated, which in this case is VQA. The model is expected to answer questions about images.
- Instruction Templates: Various instruction templates are employed to provide guidance to the model on how to process the input data. These templates can specify how the image and question should be presented to the model. For example:
- "
{Question}" A short answer to the question is;
- "
" Examine the image and respond to the following question with a brief answer: "{Question}. Answer:"; and so on.
- "
- Fine-tuning on Specific Datasets: The MM-LLM is fine-tuned using task-specific datasets that are structured according to the chosen instruction templates. These datasets can be single-turn QA or multi-turn dialogues, depending on the requirements of the task. During this phase, the model is optimized using the same objectives as in pretraining, but with a focus on the task at hand.
- Reinforcement Learning with Human Feedback (RLHF): After fine-tuning, RLHF is employed to further enhance the model's performance. RLHF involves providing feedback on the model's responses, either manually or automatically. This feedback, such as Natural Language Feedback (NLF), is used to guide the model towards generating better responses. Reinforcement learning algorithms are utilized to effectively integrate the non-differentiable NLF into the training process. The model is trained to generate responses conditioned on the provided feedback.
Therefore, the instruction tuning phase for MM-LLMs involves fine-tuning the model on task-specific datasets while providing explicit instructions and feedback to guide the learning process, ultimately improving the model's ability to perform the desired task. In the above example, we studies a specific task: Visual Question Answering.
4. State-of-the-Art MM-LLMs

Image Source: https://arxiv.org/pdf/2401.13601
The above image lists some popular SoTA MM-LLMs. At a high level, different MM-LLMs vary in several key aspects:
- Supported Modalities: MM-LLMs may support various modalities such as text, image, audio, video, and more. Some models focus on specific modalities, while others offer broader support for multiple modalities.
- Architectural Design: MM-LLMs employ different architectural designs to integrate and process multi-modal inputs. This includes variations in how modalities are fused, how attention mechanisms are applied across modalities, and the overall network structure.
- Resource Efficiency: Efficiency varies among MM-LLMs in terms of computational requirements, model size, and memory footprint. Some models prioritize resource efficiency for deployment on constrained platforms, while others prioritize performance.
- Task-Specific Capabilities: MM-LLMs may be tailored for specific tasks or domains, such as visual question answering, image captioning, dialogue generation, or cross-modal retrieval. The design and training objectives of each model are often optimized for the intended task.
- Transfer Learning and Fine-Tuning: Models may differ in their approaches to transfer learning and fine-tuning. Some models leverage pre-trained language or vision models and fine-tune them for multi-modal tasks, while others are trained from scratch on multi-modal data.
- Benchmark Performance: Performance on benchmark datasets and tasks can also vary among MM-LLMs. Models may excel in certain areas or exhibit strengths in handling specific types of data or modalities.
To choose the right MM-LLM for a specific use case, consider factors such as:
- Task Requirements: Identify the specific task or application for which the MM-LLM will be used.
- Modalities: Determine the modalities involved in your data (e.g., text, image, audio) and choose a model that supports those modalities.
- Performance Metrics: Evaluate the model's performance on relevant metrics for your task, such as accuracy, F1 score, or BLEU score on relevant benchmarks.
- Resource Constraints: Consider the computational resources available for deployment, as some models may be more resource-efficient than others.
5. Evaluating MM-LLMs
MM-LLMs can be evaluated using a variety of metrics and methodologies to assess their performance across different tasks and datasets. Here are the dimensions to evaluating MM-LLMs:
- Task-Specific Metrics: Depending on the task the MM-LLM is designed for, specific evaluation metrics can be used. For example:
- Visual Question Answering (VQA): Metrics like accuracy or F1 score can be used to evaluate the model's ability to answer questions about images. Some benchmarks include OKVQA, IconVQA, GQA etc. Some benchmarks can be found here.
- Image Captioning: Metrics such as BLEU, METEOR, or CIDEr can be used to assess the quality of generated captions compared to human-written references. Some image captioning benchmarks are available here.
- Speech Recognition: Metrics like Word Error Rate (WER) or Character Error Rate (CER) are commonly used to evaluate the accuracy of transcriptions generated by the model.
- Cross-Modal Retrieval: Evaluation metrics like Mean Average Precision (MAP) or Recall@K can be used to measure the model's performance in retrieving relevant content across different modalities.
- Human Evaluation: Human judges can assess the quality of outputs generated by the MM-LLM through subjective evaluation. This can involve tasks such as ranking generated captions or responses based on relevance, coherence, and overall quality compared to human-written counterparts.
- Zero-shot or Few-shot Learning: MM-LLMs can also be evaluated on their ability to perform tasks with minimal or no task-specific training data. This involves testing the model's performance on unseen tasks or domains, which can provide insights into its generalization capabilities.
- Adversarial Evaluation: Adversarial examples or stress tests can be used to evaluate the robustness of MM-LLMs against input perturbations or adversarial attacks.
- Downstream Task Performance: MM-LLMs are often evaluated on their performance on downstream tasks, such as image classification, text generation, or sentiment analysis, where multi-modal representations can be leveraged to improve performance.
- Transfer Learning Performance: Evaluation can also be conducted on how well the MM-LLM's representations transfer to other tasks or domains, indicating the model's ability to learn useful and generalizable representations across modalities.
6. Challenges and Future Directions
MM-LLMs represent a rapidly growing field with vast potential for both research advancements and practical applications.
Here are some promising directions to explore:
- More Powerful Models:
- Expanding Modalities: MM-LLMs can be enhanced by accommodating additional modalities beyond the current support for image, video, audio, 3D, and text. Including modalities like web pages, heat maps, and figures/tables can increase versatility.
- LLM Diversification: Incorporating various types and sizes of LLMs provides practitioners with flexibility in selecting the most suitable model for specific requirements.
- Improving MM Instruction-Tuning (IT) Dataset Quality: Enhancing the diversity of instructions in MM IT datasets can improve MM-LLMs' understanding and execution of user commands.
- Strengthening MM Generation Capabilities: While many MM-LLMs focus on MM understanding, improving MM generation capabilities, possibly through retrieval-based approaches, holds promise for enhancing overall performance.
- More Challenging Benchmarks:
- Developing benchmarks that adequately challenge MM-LLMs is essential, as existing datasets may not sufficiently test their capabilities. Constructing larger-scale benchmarks with more modalities and unified evaluation standards can help address this.
- Introducing benchmarks like GOAT-Bench, MathVista, MMMU, and BenchLMM, among others, evaluates MM-LLMs' capabilities across diverse tasks and modalities.
- Mobile/Lightweight Deployment:
- Deploying MM-LLMs on resource-constrained platforms such as mobile and IoT devices requires lightweight implementations. Research in this area, exemplified by MobileVLM and similar studies, aims to achieve efficient computation and inference with minimal resource usage.
- Integration with Domain Knowledge:
- Integrating domain-specific knowledge and ontologies into MM-LLMs can enhance their understanding and reasoning capabilities in specialized domains, leading to more accurate and contextually relevant outputs.
- Embodied Intelligence:
- Advancements in embodied intelligence enable MM-LLMs to replicate human-like perception and interaction with the environment. Works like PaLM-E and EmbodiedGPT demonstrate progress in integrating MM-LLMs with robots, but further exploration is needed to enhance autonomy.
- Multilingual and Cross-Lingual Capabilities:
- Enhancing MM-LLMs to support multiple languages and facilitate cross-lingual understanding and generation can broaden their applicability in diverse linguistic contexts.
- Privacy and Security:
- Developing techniques to ensure privacy-preserving and secure processing of multi-modal data within MM-LLMs is crucial, especially in sensitive domains like healthcare and finance.
- Explainability and Interpretability:
- Investigating methods to improve the explainability and interpretability of MM-LLMs' decisions can enhance trust and transparency in their applications, particularly in critical decision-making processes.
- Continual Learning:
- Continual learning (CL) is crucial for MM-LLMs to efficiently leverage emerging data while avoiding the high cost of retraining. Research in this area, including continual PT and IT, addresses challenges like catastrophic forgetting and negative forward transfer.
- Mitigating Hallucination:
- Hallucinations, where MM-LLMs generate descriptions of nonexistent objects without visual cues, pose a significant challenge. Strategies to mitigate hallucinations involve leveraging self-feedback as visual cues and improving training methodologies for output reliability.
References:
- MM-LLMs: Recent Advances in MultiModal Large Language Models (link)
- MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training (link)
- https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
- A Survey on Multimodal Large Language Models (link)